CrawlSpider 实现全站数据爬取
CrawlSpider 介绍
全站数据爬取的方式
-- 基于 Spider:手动请求(递归实现)
-- 基于 CrawlSpider
CrawlSpider(Spider 的一个子类)的使用
-- 创建一个工程 scrapy startproject Pro
-- cd Pro
-- 创建爬虫文件(CrawlSpider):
-- scrapy genspider -t crawl filename www.xxx.com
-- 链接提取器(LinkExtractor):
-- 作用:根据指定的规则(allow,正则表达式)进行指定链接的提取
-- 规则提取器(Rule):
-- 作用:将链接提取到的链接进行指定规则(callback)的解析
需求
使用 CrawlSpider 实现校花网明星资料的全站爬取
代码实现
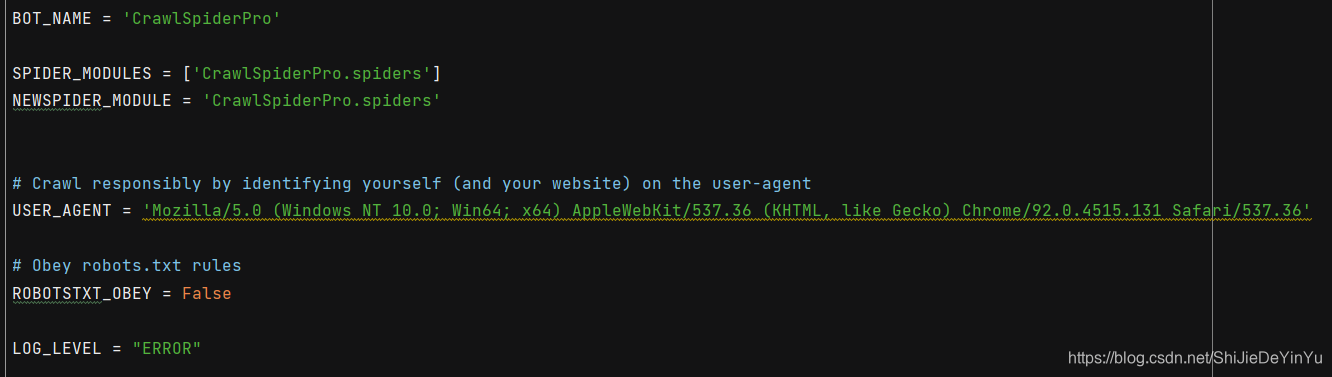
配置文件settings.py

实例化对象 items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class CrawlspiderproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
content = scrapy.Field()
pass
主文件
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from CrawlSpiderPro.items import CrawlspiderproItem
class CrawlspiderSpider(CrawlSpider):
name = 'CrawlSpider'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.521609.com/ziliao/oumei/']
# 作用:根据指定的规则(allow)进行指定链接的提取
link_index = LinkExtractor(allow = r"/ziliao/oumei/.*?.html") # 翻页的网址
link_message = LinkExtractor(allow = r"/ziliao/.*?.html") # 人物详情页的网址
# 规则提取器:将链接提取器的链接提取到的链接进行指定规则(callback)的解析
rules = (
Rule(link_index, callback = 'parse_name', follow = True),
Rule(link_message, callback = 'parse_content', follow = True)
)
def parse_name(self, response):
name_list = response.xpath('//ul/li//h3/text()').extract()
item = CrawlspiderproItem()
for name in name_list:
item["name"] =name
yield item
pass
def parse_content(self, response):
content_list = response.xpath('//span[@class="info"]//text()').extract()
item = CrawlspiderproItem()
for content in content_list:
item["content"] = content
yield item
pass
管道文件pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class CrawlspiderproPipeline:
def process_item(self, item, spider):
# 如何判定 item 类型
# 将数据写入数据库,如何保证数据的一致性
if item.__class__.__name__ == "XiaohuaproItem":
name = item["name"]
print(name)
else:
content = item["content"]
print(content)
return item
运行结果




