深度爬取——请求传参
目的
爬取 校花网 中港台明星的名字和简介
信息分别在两个页面里


思路分析
我们发现要实现这个目的,我们既要对原页面进行数据爬取,也要对详情页进行明星简介的爬取。
这时候我们似乎可以使用前面学的回调函数的方法,调用一个新的函数方法对详情页进行数据爬取。
不过这个方法还有一个问题,就是怎么保证在原页面爬取的名字数据可以和详情页的一一对应。(不考虑在详情页同时爬取名字和简介信息,不然还怎么介绍请求传参)
解决这个问题的方法就是请求传参,简单来说,就是在回调函数的时候,将已经爬取到的名字作为参数传到被调用的函数中。
听起来似乎听抽象的,那么就直接看代码好了。
代码实现
首先使前期准备工作。
配置文件。
items.py 文件的代码编写
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DataproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
content = scrapy.Field()
pass
主文件的代码编写
import scrapy
from DataPro.items import DataproItem
class StardataSpider(scrapy.Spider):
name = 'Data'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.521609.com/ziliao/gangtai/']
url = "http://www.521609.com/ziliao/gangtai/index_%s.html"
page_num = 2
def parse_detail(self, response): # 爬取详情页
content = response.xpath('//span[@class="info"]/p//text()').extract()
item = response.meta['item']
content = "".join(content)
item['content'] = content
yield item
def parse(self, response):
# 明星姓名的列表
start_name_list = response.xpath('//div[@class="page_starlist page_zllist"]/ul/li/a[2]/h3/text()').extract()
for i in range(len(start_name_list)):
item = DataproItem()
start_name = start_name_list[i]
item["name"] = start_name
# 根据姓名的位置,判断对应的详情页位置的网址位置,实现一一对应
path = '//div[@class="page_starlist page_zllist"]/ul/li[%s]/a[2]/@href' % str(i+1)
src = 'http://www.521609.com/' + response.xpath(path).extract_first()
# meta 实现请求传参,请求传参的形式是字典形式
yield scrapy.Request(url = src, callback = self.parse_detail, meta = {"item": item})
if self.page_num <= 22:
new_url = self.url % str(self.page_num)
self.page_num += 1
# 对于翻页的情况,实现回调函数
yield scrapy.Request(url = new_url, callback = self.parse)
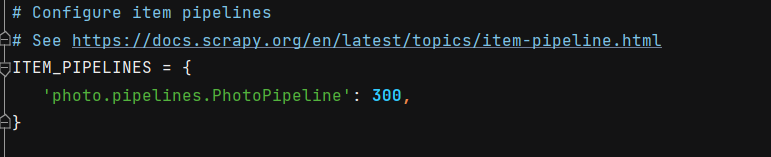
pipelines.py 文件的代码编写
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class DataproPipeline:
fp = None
def open_spider(self, spider):
self.fp = open("资料.txt", "a", encoding = "utf-8")
print("开始爬取……")
def process_item(self, item, spider):
content = item["content"]
name = item["name"]
self.fp.write(name + "\n" + content + "\n\n")
print(name, "爬取成功!")
return item
def close_spider(self, spider):
self.fp.close()
print("爬取结束!!!")
运行结果





