全站数据爬取:以校花网为例
目的
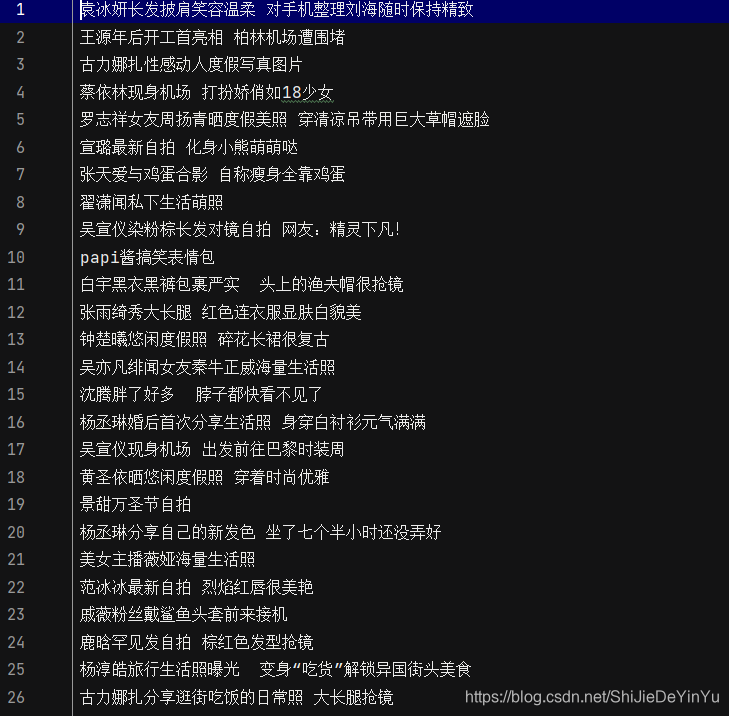
爬取 校花网 中全部照片的名称,以生活照为例。
思路分析
如果不用 scrapy 框架实现全站数据爬取其实是简单的,只要找到网址的规律一直遍历就行。那么如果要用scrapy框架实现全站数据爬取应该怎么办呢?
其实经过前面对 scrapy 框架的学习,我们发现 parse 函数方法的作用就是让我们对指定的网址网站数据解析,所以想要完成全站数据爬取,我们只需要循环调用 parse 函数方法。
我们首先也需要找到网址的规律,构造一个网址模板。
我们知道 scrapy 只会对 start_urls 列表内的内容进行发送请求,那么我们要怎么实现不停地调用 parse 函数方法呢?
这个方法就是 回调函数。
简单来说,就是在编写 parse 函数时,在函数的最后再调用一次该函数。简单来说就是递归使用 parse 函数。
明白了原理,那就试试吧,直接上代码。
代码实现
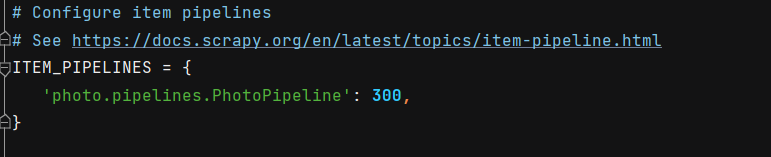
首先是配置文件。UA伪装、robots协议、日志的设置、管道的打开

主文件代码的编写
import scrapy
from photo.items import PhotoItem
class NameSpider(scrapy.Spider):
name = 'name'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.521609.com/tuku/shz/index.html']
url = "http://www.521609.com/tuku/shz/index_%s.html"
index = 2
def parse(self, response):
name_list = response.xpath('//div[@class="inn"]/ul/li/a/@title').extract()
# print(name_list)
for name in name_list:
item = PhotoItem()
item["photo_name"] = name
yield item
if self.index <= 5:
new_url = self.url % str(self.index)
# 回调函数
yield scrapy.Request(url = new_url, callback = self.parse)
self.index += 1
pass
items.py 文件的代码编写
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class PhotoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
photo_name = scrapy.Field()
pass
pipelines.py 文件的代码编写
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class PhotoPipeline:
fp = None
def open_spider(self, spider):
self.fp = open("照片名称.txt", "a", encoding = "utf-8")
print("爬虫开始……")
def process_item(self, item, spider):
photo_name = item["photo_name"]
self.fp.write(photo_name + "\n")
return item
def close_spider(self, spider):
print("爬取数据结束!!!")
self.fp.close()
运行结果