scrapy 持久化存储(以糗事百科为例)
前言
不知道大家还记得爬虫万能的三步骤吗?没错,那就是指定URL,发送请求,持久化保存数据。
我们前面在 scrapy框架(1)中简单了解了使用 scrapy 指定URL和发送请求,那么我们又要怎么使用 scrapy 实现数据的持久化存储呢?
scrapy 框架实现数据持久化存储的方法有两种,一种是基于终端命令的持久化存储;一种是基于管道的持久化存储。
基于终端指令的持久化存储
首先我们先创建相应的 scrapy 文件,用我们学过的方法完成指定URL和请求发送的步骤。
相关步骤如下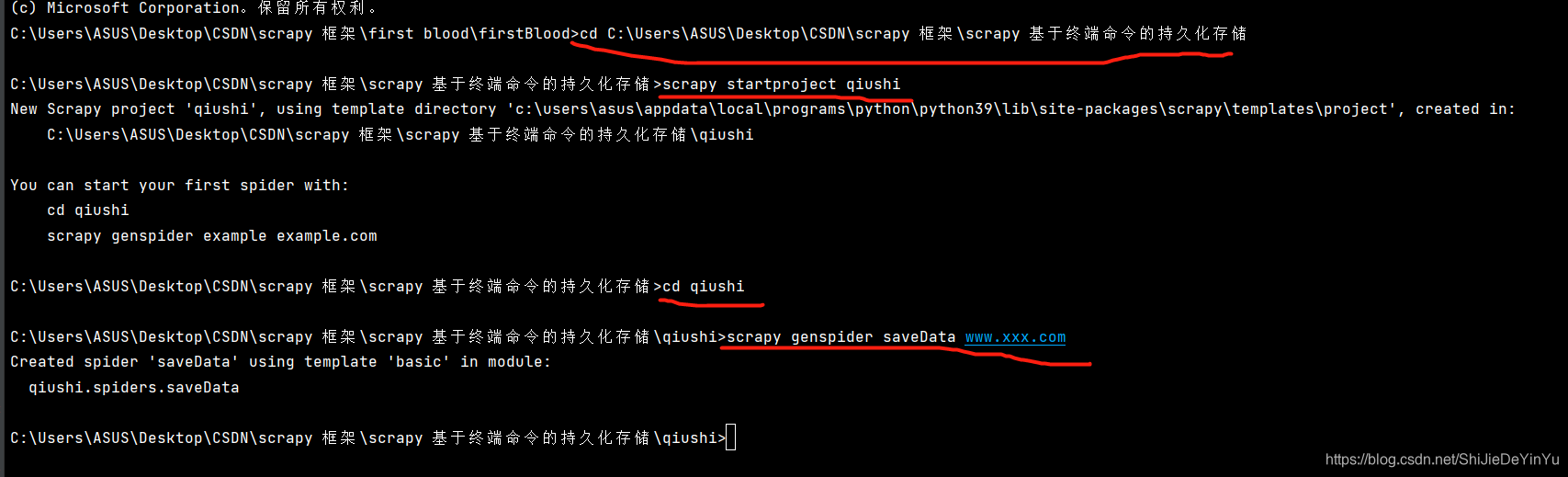
scrapy 指定URL,发送指令的文件和代码如下:
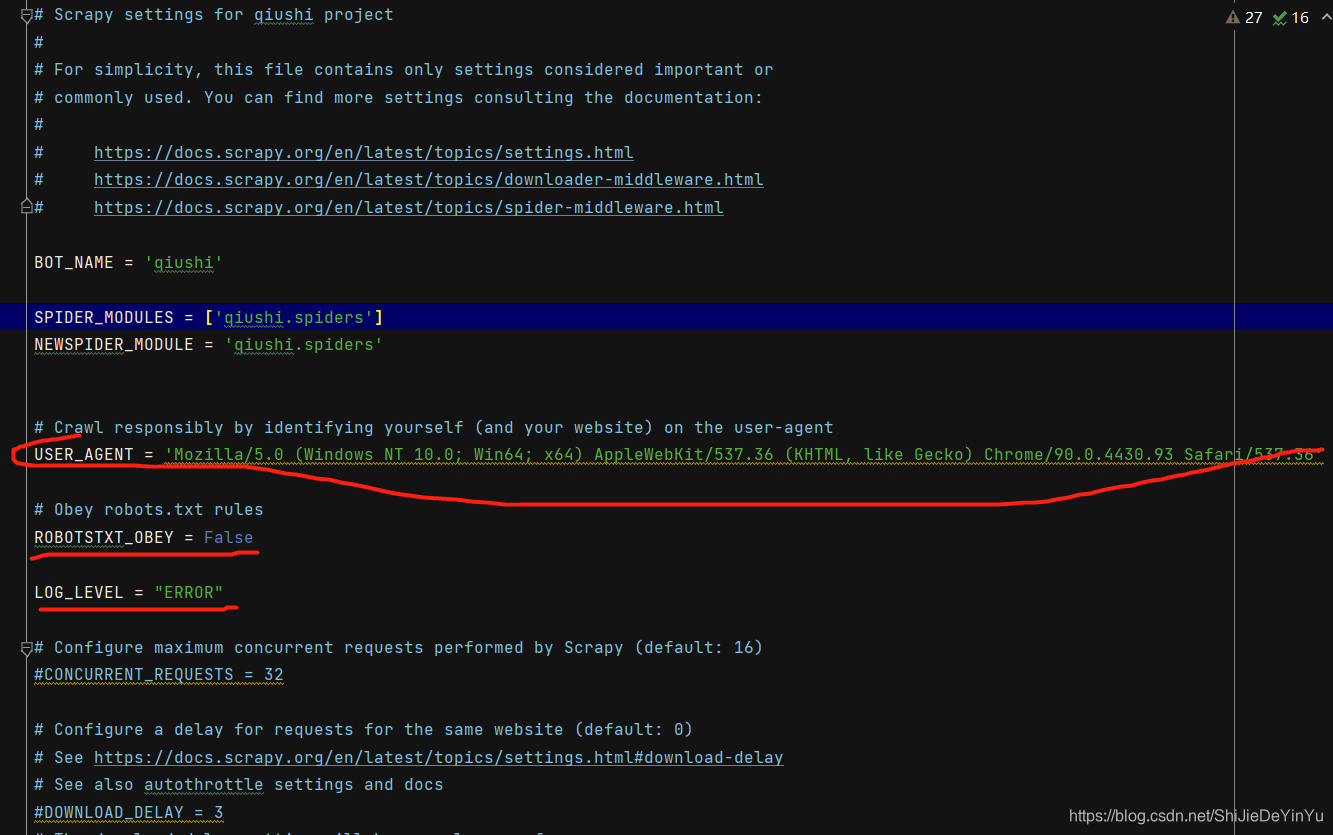
配置文件 setting.py
主代码 saveData.py
import scrapy
class SavedataSpider(scrapy.Spider):
name = 'saveData'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
# xpath 解析。作者的列表
author_list = response.xpath('//div[@class="col1 old-style-col1"]/div/div[1]/a[1]/img/@alt').extract() # 返回一个列表
# print(author_list)
for i in range(len(author_list)):
path = '//div[@class="col1 old-style-col1"]/div[%s]/a[1]/div/span//text()' % str(i+1)
content = response.xpath(path).extract()
content = "".join(content)
# print(content)
pass
接下就是基于终端指令的持久化存储了
基于终端指令的持久化存储:
—— 要求:只可以将 parse 方法中的返回值存储到本地的文本文件中
—— 注意:持久化存储的文本文件的类型只能是“json”,“jsonlines”,“jl”,“csv”,“xml”
—— 指令:scrapy crawl xxx -o filePath
—— 好处:简洁高效便捷
—— 缺点:局限性比较强(数据只可以存储到指定后缀的文本文件中)
相关文件代码如下:
相关文件items.py(其实自己加的代码并不多)
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class QiushiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()
pass
主代码saveData.py
import scrapy
class SavedataSpider(scrapy.Spider):
name = 'saveData'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
# xpath 解析。作者的列表
author_list = response.xpath('//div[@class="col1 old-style-col1"]/div/div[1]/a[1]/img/@alt').extract() # 返回一个列表
# print(author_list)
all_data = []
for i in range(len(author_list)):
path = '//div[@class="col1 old-style-col1"]/div[%s]/a[1]/div/span//text()' % str(i+1)
content = response.xpath(path).extract()
content = "".join(content)
author = author_list[i]
# print(content)
data = {
"author": author,
"content": content
}
all_data.append(data)
return all_data
终端指令
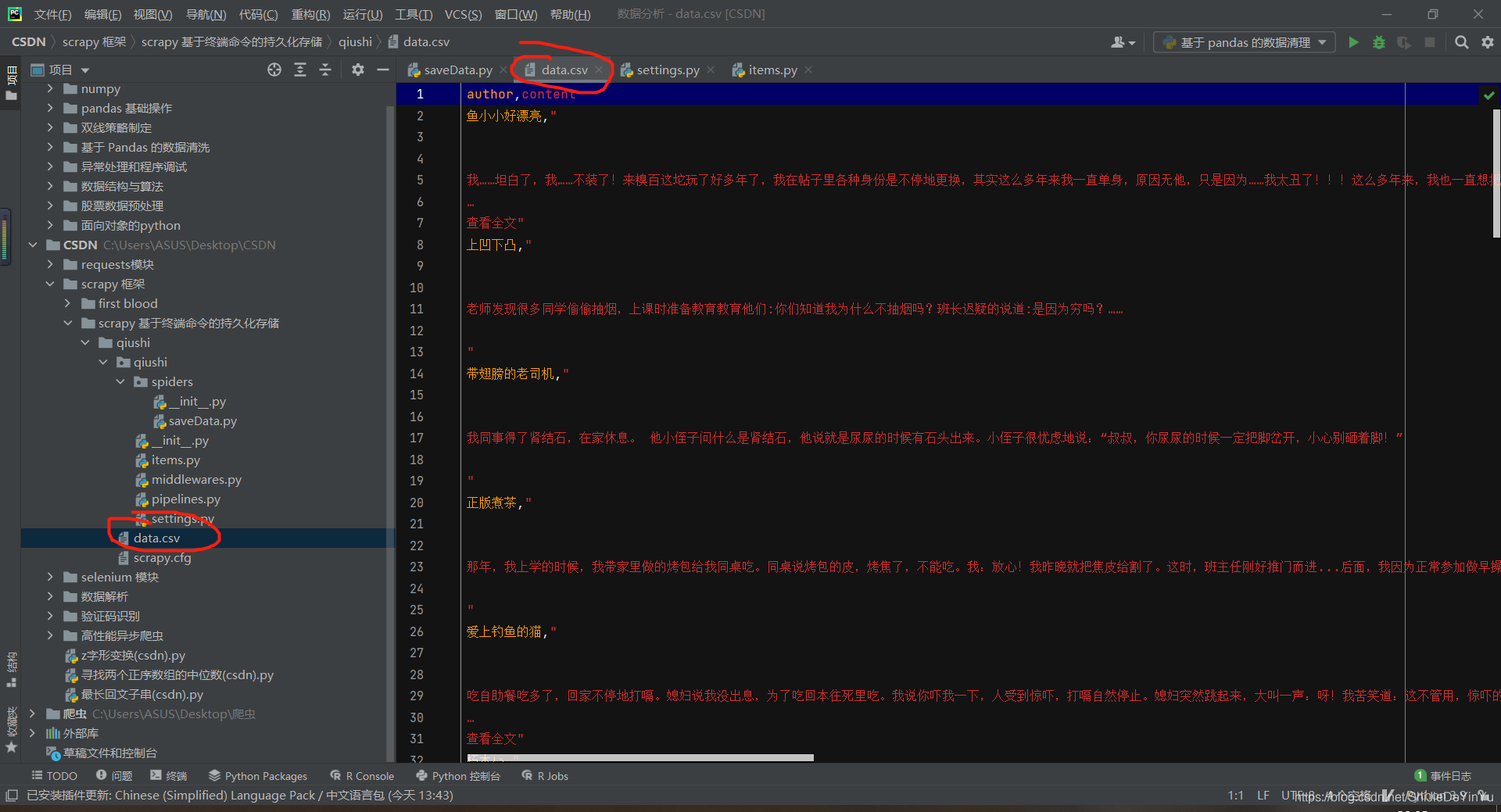
运行结果
基于管道的持久化存储
我们可以发现基于终端指令的局限性其实很大,所以我们通常不使用基于终端命令的方法进行数据的持久化存储。那么就是基于管道的持久化存储了。
前期工作和基于终端的持久化存储一样。只是在配置文件要做出一点改变。
其中items.py不需要改变。配置文件settings.py基本不变,只需要打开管道就行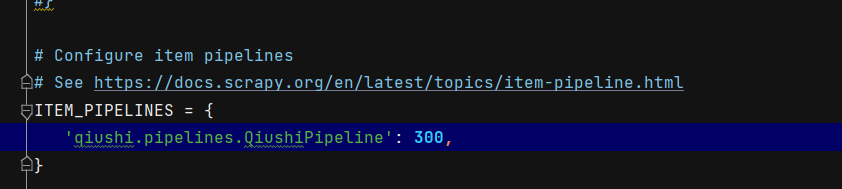
先是管道文件 pipelines.py 的代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class QiushiPipeline:
fp = None
def open_spider(self, spider): # 打开爬虫,函数名一定要是这个。只被调用一次
print("开始爬虫……")
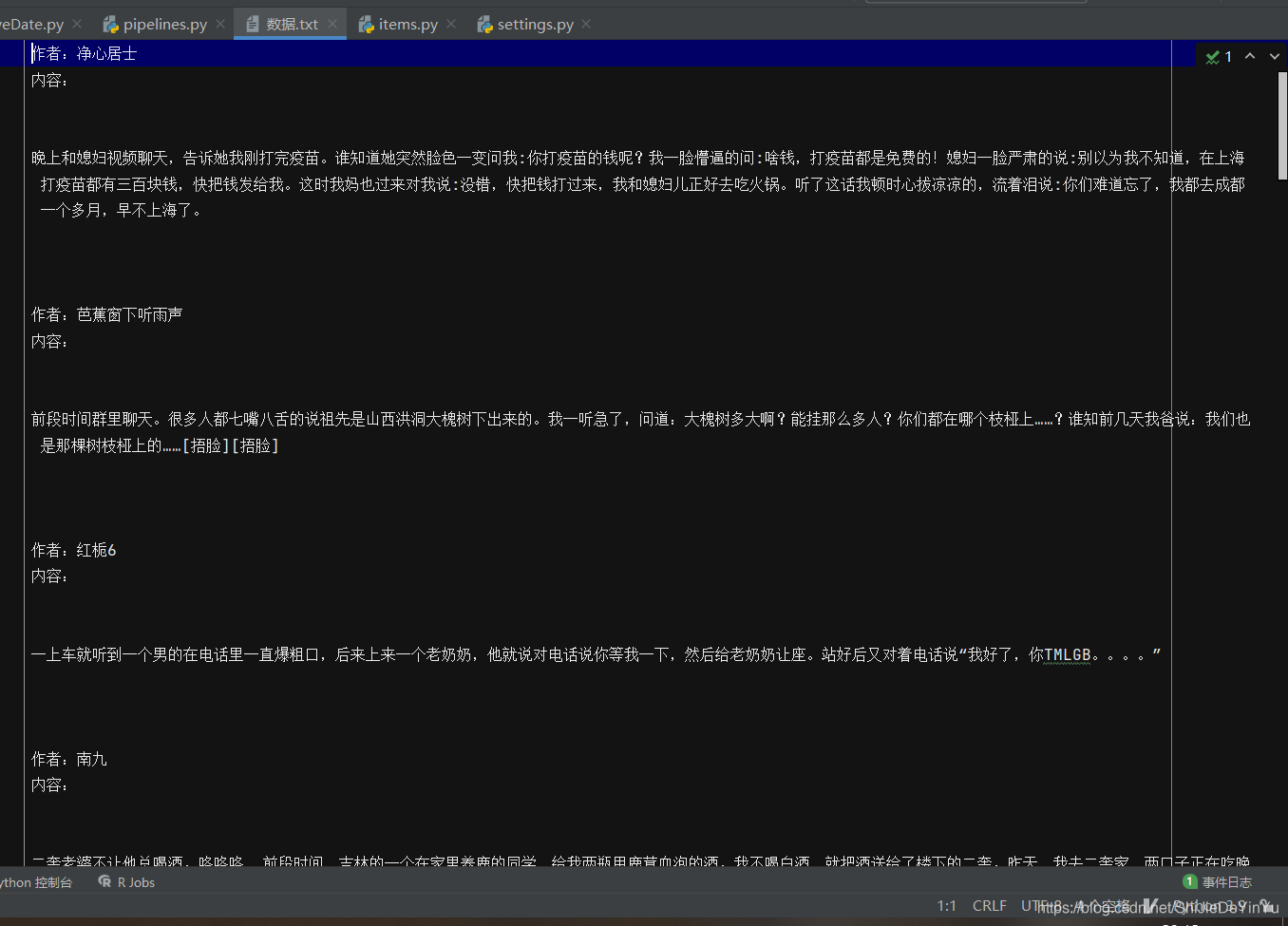
self.fp = open("数据.txt", "a", encoding = "utf-8")
def process_item(self, item, spider): # 每传入一个参数,就调用一次
author = item["author"]
content = item["content"]
self.fp.write("作者:" + author + "\n")
self.fp.write("内容:" + content + "\n" + "\n")
return item
def close_spider(self, spider):
print("爬虫结束!!!")
self.fp.close()
然后是主代码 saveDate.py
import scrapy
from qiushi.items import QiushiItem # 导入 items.py 文件中函数
class SavedateSpider(scrapy.Spider):
name = 'saveDate'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
# xpath 解析。作者的列表
author_list = response.xpath('//div[@class="col1 old-style-col1"]/div/div[1]/a[1]/img/@alt').extract() # 返回一个列表
# print(author_list)
item = QiushiItem()
for i in range(len(author_list)):
path = '//div[@class="col1 old-style-col1"]/div[%s]/a[1]/div/span//text()' % str(i + 1)
content = response.xpath(path).extract()
content = "".join(content)
author = author_list[i]
item["author"] = author
item["content"] = content
yield item
我们试着运行一下代码,结果如下: