爬虫小项目 —— 京东商品评价内容爬取
前言
会写这么一个类似“小项目”的程序是因为在前年(去年?)的时候,一位老师需要用爬虫爬取京东某类商品的用户评论数据——不知道为什么会找学生写这种程序,淘宝找一个或许都比我靠谱吧?
虽然我最后写出了一个勉强可运行的程序,也爬取到了一些评论数据,但我一直认为那位老师只是不知道怎么说我写的东西不行,毕竟在隔了一两年的今天我再看这段代码,其实写的很差,封装性基本没有,适应性差的要命,所以我才会突然说再写一遍,但当然结果也就是比之前的代码好上一点。
前提准备
前提准备
注意:因为谷歌浏览器的升级以及驱动器相关版本不对应,所以使用的是 edge 浏览器的 自动测试,并且使用无头浏览器,但是其实 selenium.webdriver.edge.EdgeOptions中并没有EdgeOptions模块,所以需要自己写,这是我百度使用的代码
我电脑的文件目录如下:C:\Users\ASUS\AppData\Local\Programs\Python\Python39\Lib\site-packages\selenium\webdriver\edge
文件代码如下:
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
class EdgeOptions:
KEY = "ms:edgeOptions"
def __init__(self):
self._arguments = []
self._experimental_options = {}
self._caps = DesiredCapabilities.EDGE.copy()
@property
def arguments(self):
return self._arguments
@property
def experimental_options(self):
return self._experimental_options
def add_argument(self, argument):
"""
添加浏览器参数
:param argument: 启动参数
"""
if argument:
if self._is_infobars(argument):
self._enable_infobars()
else:
self._arguments.append(argument)
else:
raise ValueError("argument参数不能为空")
def add_arguments(self, arguments: list or tuple):
"""
同时添加多个浏览器参数
:param arguments: 启动参数集
"""
if arguments:
if isinstance(arguments, str):
self.add_argument(arguments)
else:
for arg in arguments:
if self._is_infobars(arg):
self._enable_infobars()
else:
self._arguments.append(arg)
else:
raise ValueError("argument参数不能为空")
@staticmethod
def _is_infobars(string):
return string == "--disable-infobars"
def _enable_infobars(self):
"""
启用'禁用浏览器正在被自动化程序控制的提示'启动参数
"""
self._experimental_options["excludeSwitches"] = ["enable-automation"]
def to_capabilities(self):
"""
使用已设置的所有选项创建功能
:return: 返回包含所有内容的字典
"""
caps = self._caps
edge_options = {
"extensions": [],
"args": self.arguments
}
edge_options.update(self.experimental_options)
caps[self.KEY] = edge_options
return caps
项目目录

完整代码
lib文件夹下 main.py
import os,sys
FilePath = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(FilePath) # 将 JingDongProject 的路径置入环境变量
if __name__ == '__main__':
from bin import Spider_JingDong
Spider_JingDong.spride()
bin文件夹下 Spider_JingDong.py
from core import Really_Sprider
class spride:
def __init__(self):
print("{}Running{}".format("-"*20, "-"*20))
Really_Sprider.really_sprider()
conf文件夹下 Setting.py
URL = "https://www.jd.com/"
# 休眠等待的问题,有时候要等待网页加载或者说怕被检验,但很有可能是我网速的问题
SLEEPTIME = 2
# 一开始下载的商品评论 txt 文件默认下载地址
DOWNLOAD_PATH = r'C:\Users\ASUS\Desktop\code\JingDongProject\download\download.txt'
# 将下载的 txt文件 内容存储到 xlsx 文件中的下载地址
EXCEL_PATH = r'C:\Users\ASUS\Desktop\code\JingDongProject\download\data.xlsx'
# 需要爬取的商品页数
PAGE = 2
# 每页搜索的商品数(最多到61,京东一页商品最多60个,因为使用 for 循环所有选择 60+1),最好保证爬取页数页面所有的商品数量 >= PURE_PAGE_NUM,否则会超出索引
PURE_PAGE_NUM = 3
# 评论页数
GOODS_PAGE = 2
core文件夹下 really_spider.py 文件
# 使用的是 edge 浏览器的 自动测试
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.edge.EdgeOptions import EdgeOptions
from time import sleep
from lxml import etree
import os
from conf import Setting
class really_sprider:
def __init__(self):
self.search_name()
self.search_option()
self.search()
def search_name(self): # 输入商品名称
self.name = input("输入您想要搜素的商品名称:")
# print(name)
def search_option(self): # 选择商品排序方式
while True:
tip = """
---------------------------------------------
选择商品排序方式(输入数字)
---------------------------------------------
1. 综合
2. 销量
3. 评论数
----------------------------------------------
"""
print(tip)
self.num = input("选择商品排序方式(输入数字):")
if not self.num.isdigit():
continue
elif int(self.num) > 3 or int(self.num) <= 0:
continue
num = int(self.num)
break
def start_webdriver(self): # 启动浏览器
# 1.创建Edge浏览器对象,这会在电脑上在打开一个浏览器窗口
options = EdgeOptions()
options.add_arguments([r"--headless", r"--disable-gpu"]) # 无头浏览器
self.driver = webdriver.Edge(capabilities=options.to_capabilities())
# self.driver = webdriver.Edge()
# 2.通过浏览器向服务器发送URL请求
self.driver.get(Setting.URL)
self.Sleep()
def search(self): # 点击搜索之后的页面
self.click_search()
self.line_way()
# 获取此时的页面源码
page = self.driver.page_source
# xpath 解析
tree = etree.HTML(page)
page = int(tree.xpath('//*[@id="J_topPage"]/span/i/text()')[0])
page = min(page, Setting.PAGE)
for page in range(1, Setting.PAGE + 1):
self.click_good() # 点击商品进入商品详情页
# 点击下一页
next_page = self.driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[1]/a[9]')
self.driver.execute_script('arguments[0].click()', next_page)
self.driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
self.Sleep()
def click_search(self): # 输入商品名称并点击搜索
self.start_webdriver()
# 输入商品名称
name_input = self.driver.find_element_by_id("key")
name_input.send_keys(self.name)
self.Sleep()
# 点击搜索
click = self.driver.find_element_by_xpath('//*[@id="search"]/div/div[2]/button')
self.driver.execute_script('arguments[0].click()', click)
self.Sleep()
# 滚动加载该页面所有商品
self.driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
self.Sleep()
def line_way(self): # 点击排序方式
xpath = '//*[@id="J_filter"]/div[1]/div[1]/a[{}]'.format(self.num)
sales_count = self.driver.find_element_by_xpath(xpath)
self.driver.execute_script('arguments[0].click()', sales_count)
self.Sleep()
def click_good(self): # 点击进入商品详情页
for index in range(1, Setting.PURE_PAGE_NUM):
# 获取商品名称
# 获取此时的页面源码
page = self.driver.page_source
# xpath 解析
tree = etree.HTML(page)
self.goods_name = tree.xpath('//*[@id="J_goodsList"]/ul/li[{}]/div/div[4]/a/em/text()'.format(index))
num = ""
for i in self.goods_name:
i = i.replace(" ", "")
i = i.replace("\n", "")
i = i.replace("\t", "")
num += i
self.goods_name = num
print(self.goods_name)
# 进入商品详情页面
xpath = '//*[@id="J_goodsList"]/ul/li[{}]/div/div[1]/a'.format(index)
good_detail = self.driver.find_element_by_xpath(xpath)
self.driver.execute_script('arguments[0].click()', good_detail)
self.Sleep()
# 商品评价下载
self.comment_download()
def comment_download(self): # 商品评价下载
self.new_window()
# 滑到底部,等待评论加载完成
comment_box = self.driver.find_element_by_xpath('//*[@id="detail"]/div[1]/ul/li[5]')
self.driver.execute_script('arguments[0].click()', comment_box)
self.driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
self.Sleep()
# 获取此时的页面源码
page = self.driver.page_source
# xpath 解析
tree = etree.HTML(page)
page = tree.xpath('//*[@id="comment"]/div[2]/div[2]/div[1]/ul/li[1]/a/em/text()')[0]
if "+" in page and "万" in page:
page = Setting.GOODS_PAGE
for p in range(1, page + 1):
for i in range(1, 11):
self.content(i)
# 点击下一页
if p == 1:
next_page = self.driver.find_element_by_xpath('//*[@id="comment-0"]/div[12]/div/div/a[7]')
elif p < 5:
next_page = self.driver.find_element_by_xpath('//*[@id="comment-0"]/div[12]/div/div/a[8]')
else:
next_page = self.driver.find_element_by_xpath('//*[@id="comment-0"]/div[12]/div/div/a[8]')
self.driver.execute_script('arguments[0].click()', next_page)
self.driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
self.Sleep()
self.close_window()
def new_window(self):
# 获取窗口,返回为一个列表
handles = self.driver.window_handles
# 最后一个是新打开的窗口,跳转到这个窗口
self.driver.switch_to.window(handles[-1])
def close_window(self):
# 关闭新打开的窗口
self.driver.close()
handles = self.driver.window_handles
self.driver.switch_to.window(handles[0])
def content(self, index): # 获取评价,包括商品名称、用户名、是否是会员,评分星级,评价文字内容
"""
xpath 解析
//*[@id="comment-0"]/div[1]
"""
# 获取此时的页面源码
page = self.driver.page_source
# xpath 解析
tree = etree.HTML(page)
# 用户名
username = tree.xpath('//*[@id="comment-0"]/div[{}]/div[1]/div[1]/text()'.format(index))[1].strip(" ")
# 是否是会员
huiyuan = tree.xpath('//*[@id="comment-0"]/div[{}]/div[1]/div[2]/a/text()'.format(index))
if len(huiyuan) == 0:
huiyuan = "None"
else:
huiyuan = huiyuan[0]
# 评价内容
content = tree.xpath('//*[@id="comment-0"]/div[{}]/div[2]/p/text()'.format(index))[0]
# 星级
star = tree.xpath('//*[@id="comment-0"]/div[{}]/div[2]/div[1]/@class'.format(index))[0][-5:]
# print(star)
with open(Setting.DOWNLOAD_PATH, "a", encoding="utf-8")as f:
f.write(self.goods_name + "|" + username + "|" + huiyuan + "|" + star + "|" + content)
f.write("\n")
def Sleep(self):
sleep(Setting.SLEEPTIME)
download 文件夹下 ToExcel.py
import os,sys
path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(path)
if __name__ == '__main__':
from conf.Setting import DOWNLOAD_PATH,EXCEL_PATH
from openpyxl import Workbook
book = Workbook()
sheet = book.active
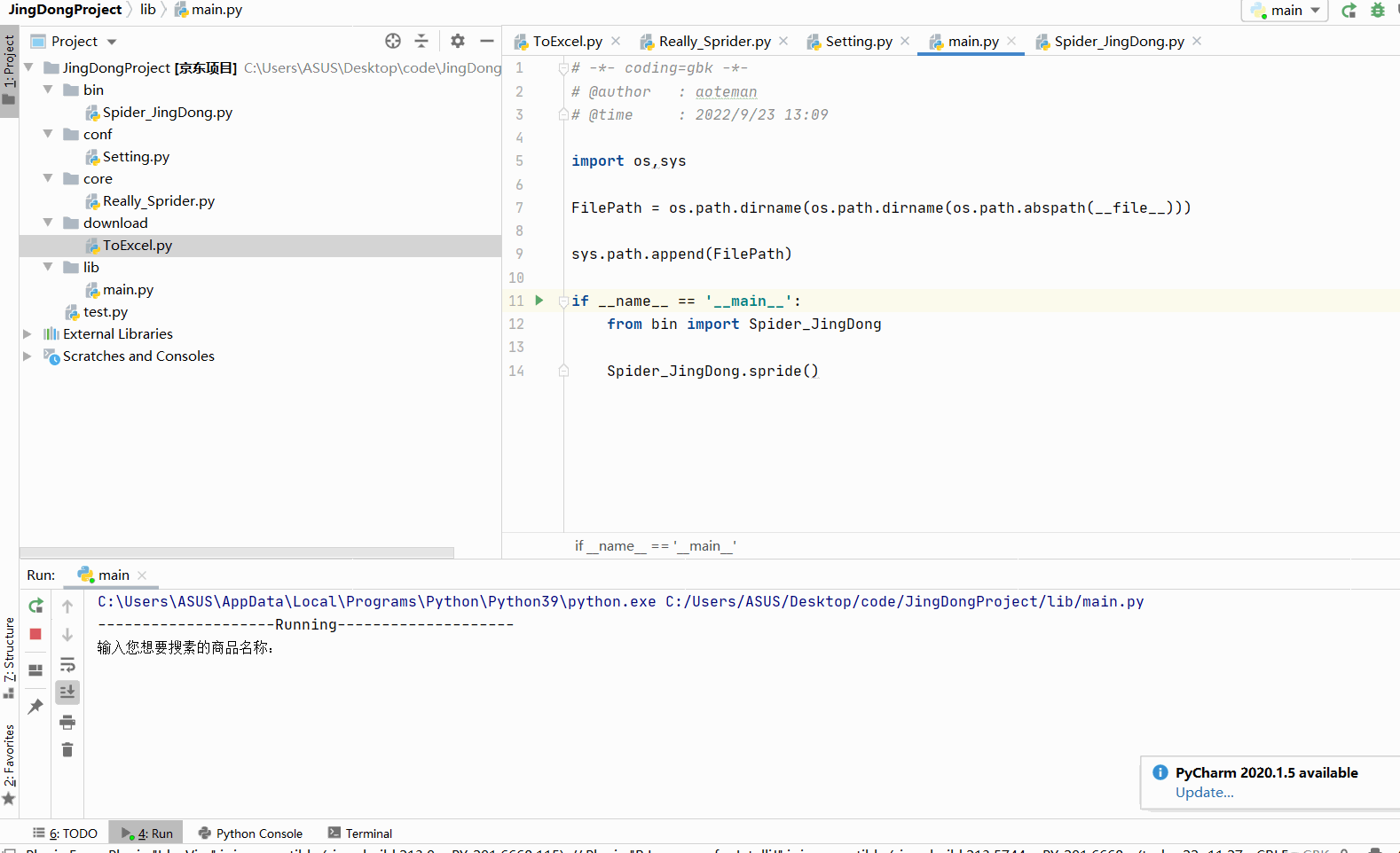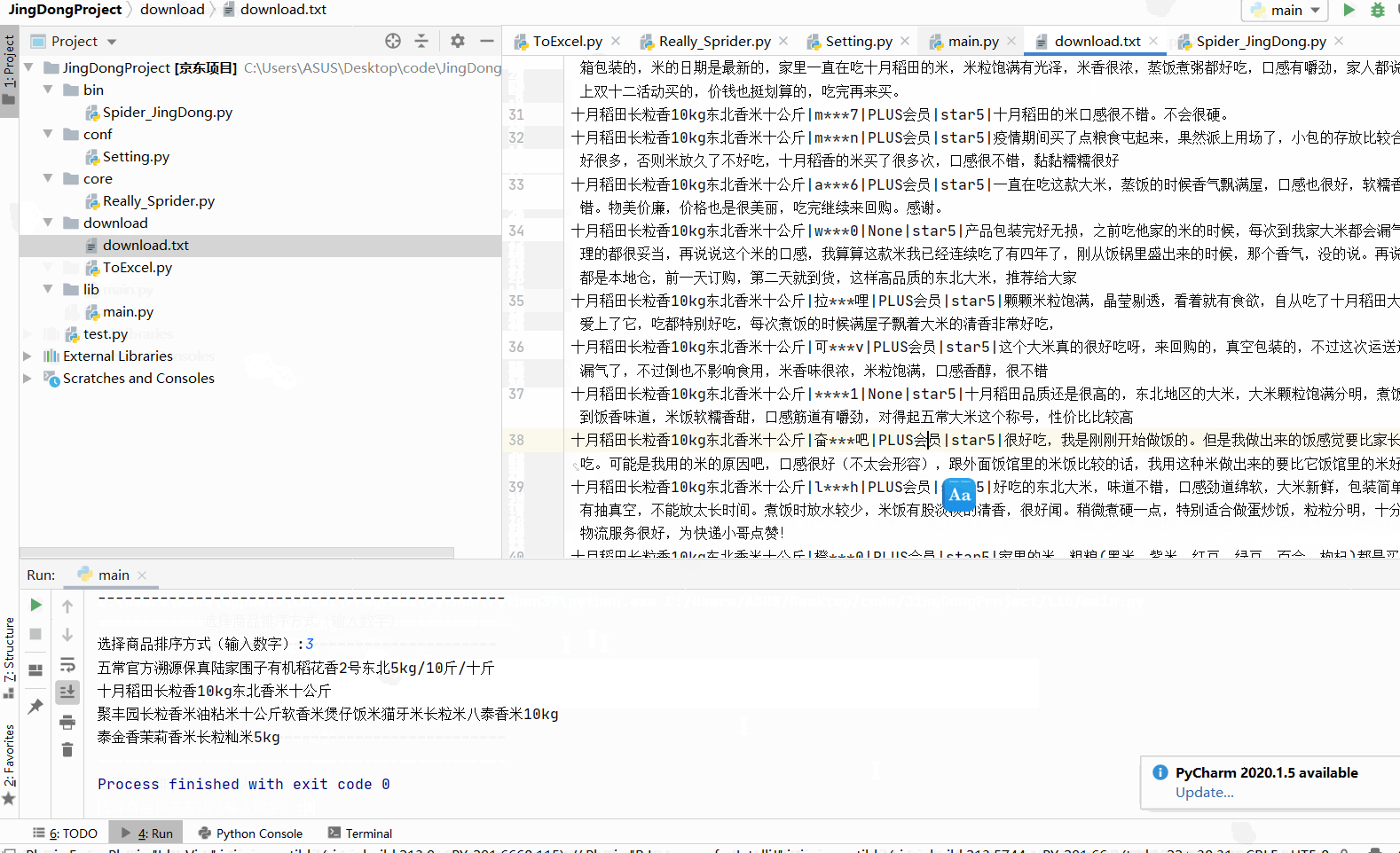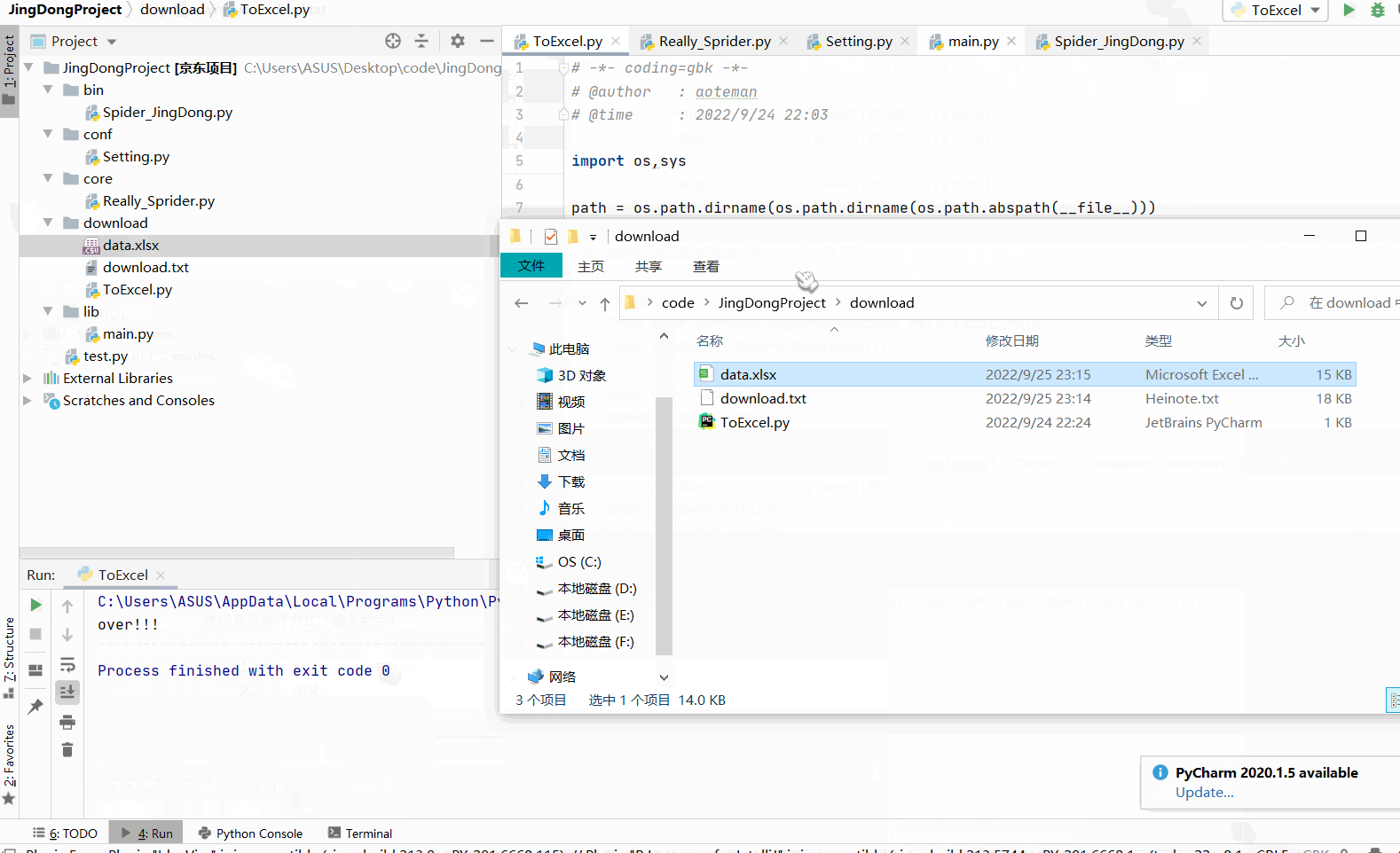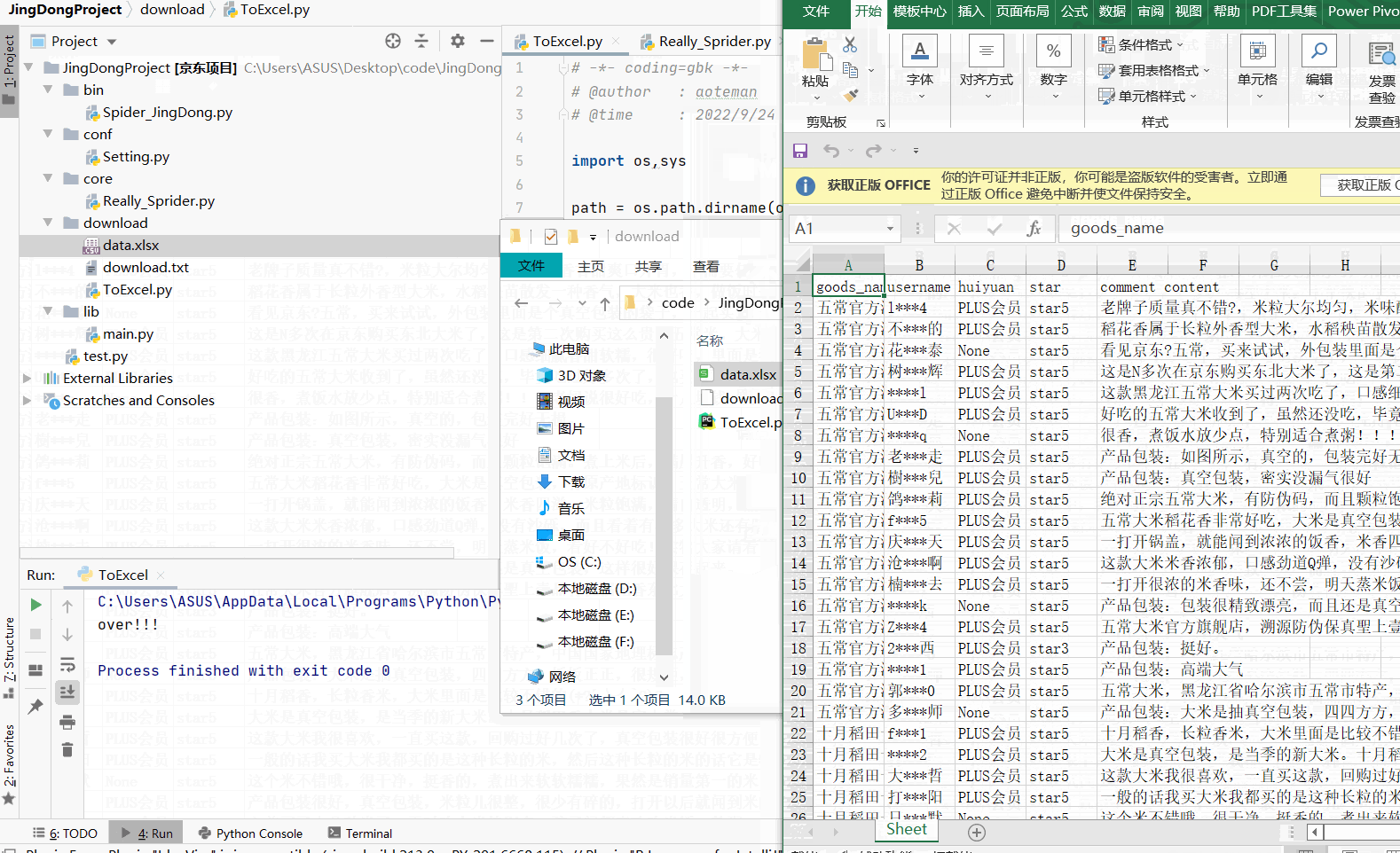
title = ("goods_name", "username", "huiyuan", "star", "comment content")
sheet.append(title)
if os.path.isfile(DOWNLOAD_PATH):
with open(DOWNLOAD_PATH, "r", encoding="utf-8") as f:
for line in f:
line_list = line.split("|")
# self.goods_name + "|" + username + "|" + huiyuan + "|" + star + "|" + content
sheet.append(line_list)
book.save(EXCEL_PATH)
print("over!!!")
else:
print("can't find the DOANLOAD file!!!")
注意事项或者说是 Bug
- 所要爬取商品页数一定是存在的,不能超过该商品页面的总页数
- 保证每页要爬取的商品数量都存在,即:需要在该页面爬取5个商品,但实际上该页面只有3个商品
- 因为某些原因(当时没有找到解决方法,现在知道了不想在上面直接改了),目前爬取的商品评价是过万的商品的评价,所以未过万的商品评论并不会下载
- 商品名称的问题,后来才发现京东上一些商品是有缩略图的,如下图我圈起来的部分;所以一些商品在爬取过程中是没有名字下载的,因为我参考的姓名定位是有缩略图的名字,所以无缩略图的商品爬取过程中是没有名字的(当时没有找到解决方法,现在知道了不想在上面直接改了)
一个小坑
因为还存在这些小问题,并且一些问题已经找到解决办法了,所以在最近国庆前后会写一个修改版的代码,应该会加上简单的 PyQt5 界面。
演示