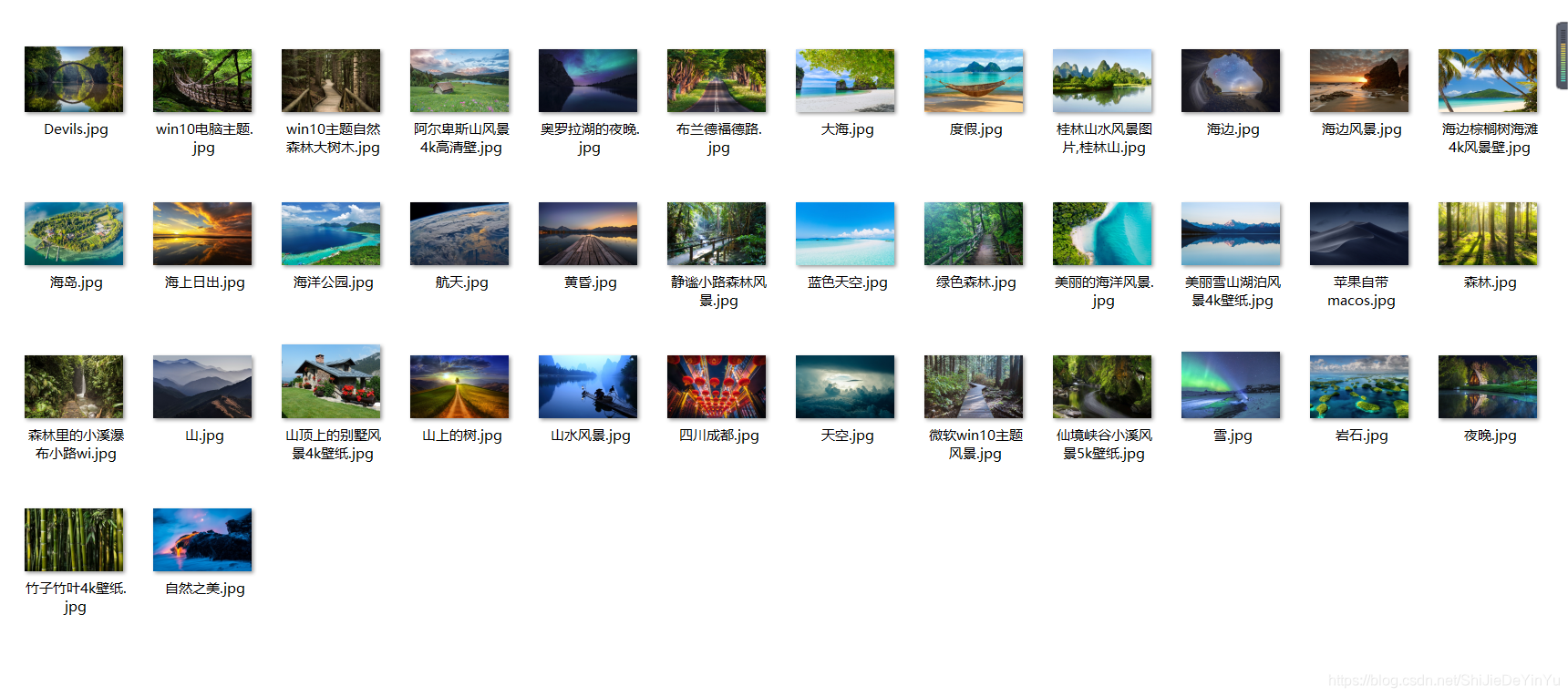
用 aiohttp 完成异步爬取图片
代码演示
import asyncio
import requests
from lxml import etree
import aiohttp
import time
import os
async def get_photo(url, name):
print("正在下载:", name)
# UA伪装
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
async with aiohttp.ClientSession() as session:
async with await session.get(url = url, headers = header) as response:
photo = await response.read()
with open('C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\协程\\aiohttp 异步爬取图片\\' + name + ".jpg", "wb") as fp:
fp.write(photo)
print("下载完成", name)
if __name__ == '__main__':
# 开始时间
start = time.time()
# 创建文件夹
if not os.path.exists('C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\协程\\aiohttp 异步爬取图片'):
os.mkdir('C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\协程\\aiohttp 异步爬取图片')
# UA伪装
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
tasks = []
# 指定url, 发送请求
for index in range(2):
if index == 0:
url = "https://pic.netbian.com/4kfengjing/index.html"
else:
url = 'https://pic.netbian.com/4kfengjing/index_%s.html' % str(index+1)
response = requests.get(url = url).text
response = response.encode('iso-8859-1').decode('gbk')
# xpath 解析
tree = etree.HTML(response)
li_list = tree.xpath('//*[@id="main"]/div[3]/ul/li')
for li in li_list:
src = li.xpath('a/img/@src')[0]
name = li.xpath('a//text()')[0].split(" ")[0]
task = asyncio.ensure_future( get_photo("https://pic.netbian.com" + src, name) )
tasks.append(task)
# 协程
loop = asyncio.get_event_loop()
loop.run_until_complete( asyncio.wait(tasks) )
print("over!!!")
print()
print(time.time() - start)
看一下运行结果