resquests 协程的尝试
前面我们学习了协程的简单的语法,以及写了一段代码实现了简单的协程。而我们的目的是为了实现异步爬虫。所以我们就用 requests 模块尝试一下协程
flask服务
首先我们用 flask 设置一个简单的框架,因为我们的重点是协程,所以选择的网站越简单越好
代码如下
app = Flask(__name__)
@app.route('/bobo')
def index_bobo():
time.sleep(2)
return "hello bobo"
@app.route('/jay')
def index_jay():
time.sleep(2)
return "hello jay"
@app.route("/tom")
def index_tom():
time.sleep(2)
return "hello tom"
if __name__ == '__main__':
app.run(threaded = True)
运行结果如下

我们会看到一个 url ,那个就是我们通过 flask 框架得到的一个根目录
resquests 模块的尝试
有了前期的准备工作,我们就可以试着通过 requests 模块进行协程的实现。
根据之前所学进行代码的编写
import asyncio
import requests
import time
async def get_url(url):
print("正在下载", url)
await asyncio.sleep(2)
response = requests.get(url = 'http://127.0.0.1:5000/' + url)
print("下载成功,", response.text)
if __name__ == '__main__':
start = time.time()
urls = ['bobo', "jay", "tom"]
tasks = []
for url in urls:
task = asyncio.ensure_future( get_url(url) )
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete( asyncio.wait( tasks ))
print(time.time() - start)
但我们一运行程序就发现不对劲了,
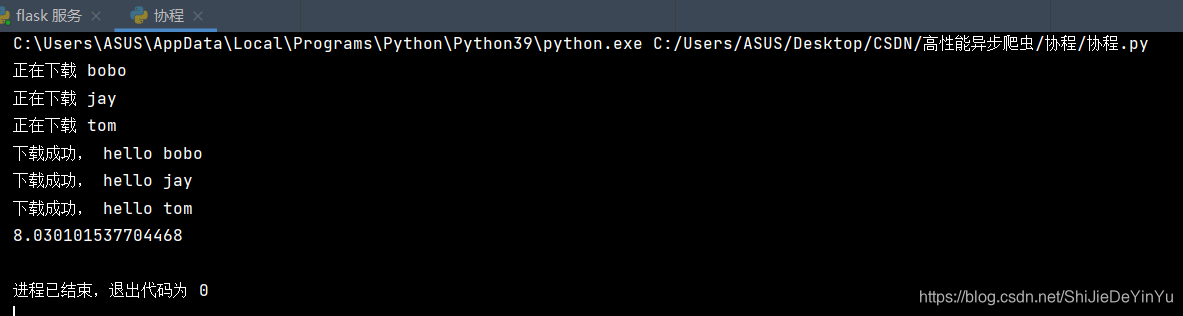
明明我们使用了协程,为什么时间反而没有什么变化呢?这究竟是为什么呢?
aiohttp 模块实现协程
上面我们发现 requests 模块实现不了协程。这是为什么呢?
其实原因很简单,requests.get 是基于同步,要想实现协程必须使用基于异步的网络请求模块进行 url 的请求发送。所以我们使用 aiohttp模块,基于异步的网络请求模块。
至于怎么使用 aiohttp ,就直接看代码好了
import asyncio
import aiohttp
import time
async def get_url(url):
print("正在下载", url)
async with aiohttp.ClientSession() as session:
async with await session.get(url = 'http://127.0.0.1:5000/' + url) as response:
# text() 返回字符串形式的数据类型
# read() 返回二进制形式的数据类型
# json() 返回json串形式的数据类型
# 注意:获取响应数据类型之前一定要用 await 进行手动挂起
page = await response.text()
print("下载成功,", page)
if __name__ == '__main__':
start = time.time()
urls = ['bobo', "jay", "tom"]
tasks = []
for url in urls:
task = asyncio.ensure_future( get_url(url) )
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete( asyncio.wait( tasks ))
print(time.time() - start)
让我们来看一些运行结果,看看是不是空欢喜一场
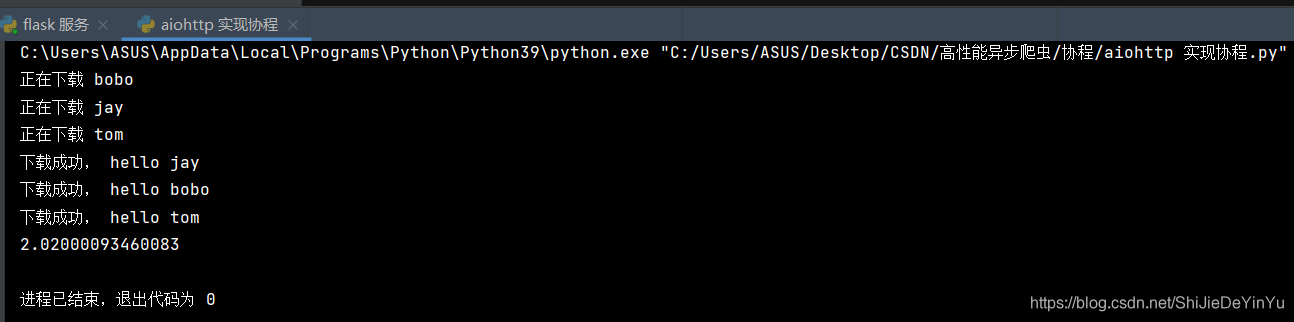
运行时间确实是两秒,说明我们使用 aiohttp 实现了协程。



