selenium 模块自动化操作(2)(以京东为例)
页面滚动
我们首先打开京东的页面,随便输入一个商品名称会看到如下的页面。
我们可以先数一数页面有多少商品。
如果我们使用滚轮滚动,我们就会发现在也页面滚动的时候页面同时也在不停地加载。
如果我们使用抓包工具,解析网页源码,在页面不滚动的情况下我们发现商品的数量是30个。
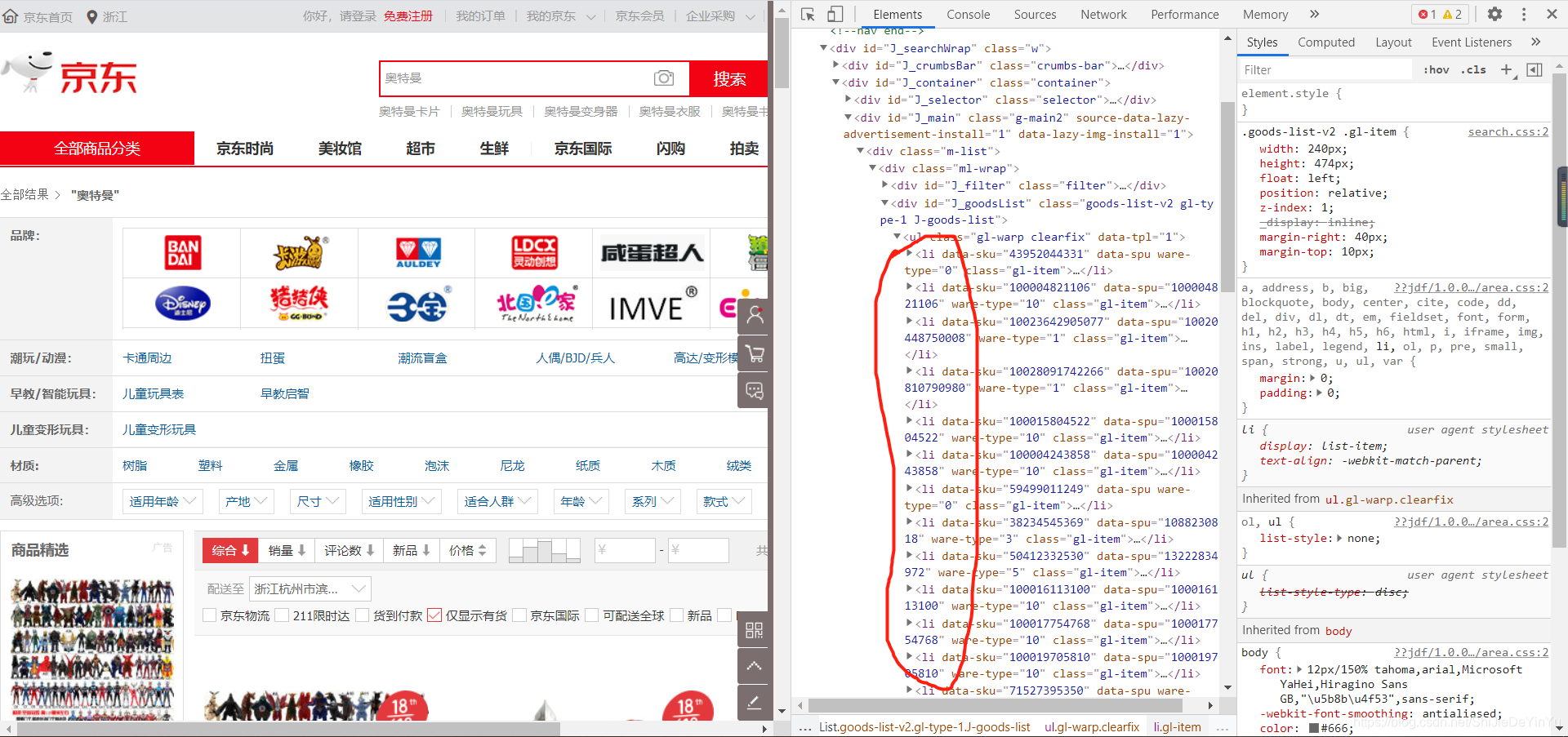
也就是这时候 li 标签只有 30 个,如果我们把页面拉到底部,再看页面有的商品我们就会发现这时候有 60 个 li 标签
这也意味着多出来的 30 个商品是动态加载的数据,是不能直接通过 selenium 的 xpath 直接解析得到的,需要手动让它加载之后再进行 xapth 解析。
这就需要代码模拟页面滚动的操作。
代码如下:
from selenium import webdriver
from time import sleep
if __name__ == '__main__':
bro = webdriver.Chrome(executable_path = "chromedriver.exe")
bro.get("https://search.jd.com/Search?keyword=%E5%A5%A5%E7%89%B9%E6%9B%BC&enc=utf-8&wq=%E5%A5%A5%E7%89%B9%E6%9B%BC&pvid=52ea37a1c5614b668de352ffb60c7960")
sleep(2)
# 使用 javascript 命令 模拟页面滚动
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
使用 javescript 命令实现鼠标点击
如果我们真的需要爬取京东的商品信息,一页信息肯定是不够的,这就需要我们模拟完成翻页。
按前面所学,我们可以先通过 xpath 解析得到按钮的信息,再使用 click() 方法实现模拟点击。
但实际上我们明明定位到了正确的元素,但程序会告诉我们此元素无法被点击。这是因为按钮上方有文字覆盖,比如说 “下一页” 。所以我们使用 javescript 命令实现按钮的点击。
接上述代码
sleep(2)
# 定位到按钮(下一页)的位置
btn = bro.find_element_by_class_name('pn-next')
bro.execute_script('arguments[0].click()', btn)
窗口的切换
有时候我们可能需要商品详情页的信息,这样一来我们就需要对先打开的窗口进行 xpath 解析了。但现在我们的浏览器的页面其实一直停留在一开始打开的窗口,也就是说虽然向我们展示的是新打开的窗口,但实际上我们的自动化浏览器仍停留在原始的页面。
所以需要我们用代码实现窗口的转换
代码如下。接上述代码
# 获取窗口,返回为一个列表
handles = bro.window_handles
print(handles)
# 最后一个是新打开的窗口,跳转到这个窗口
bro.switch_to.window(handles[-1])
# 滑到底部
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
# 关闭新打开的窗口
bro.close()
sleep(2)
# 退出
bro.quit()



