selenium 自动化操作(1)(以百度翻译为例)
from selenium import webdriver
if __name__ == '__main__':
bro = webdriver.Chrome(executable_path = "chromedriver.exe")
# 发起请求
bro.get('https://fanyi.baidu.com/')
我们运行程序发现我们使用 selenium 请求到的网页和我们自己打开的网页有一点不同。
使用 selenium 请求到的网页多了一个页面窗口。

那么我们要怎么使用 selenium 关闭这个窗口呢?
我们可以使用元素的 xpath 路径,元素的 id 名,或者说元素的属性定位到关闭的符号,并且使用 click() 方法模拟鼠标的点击。
这是定位元素的一些方法
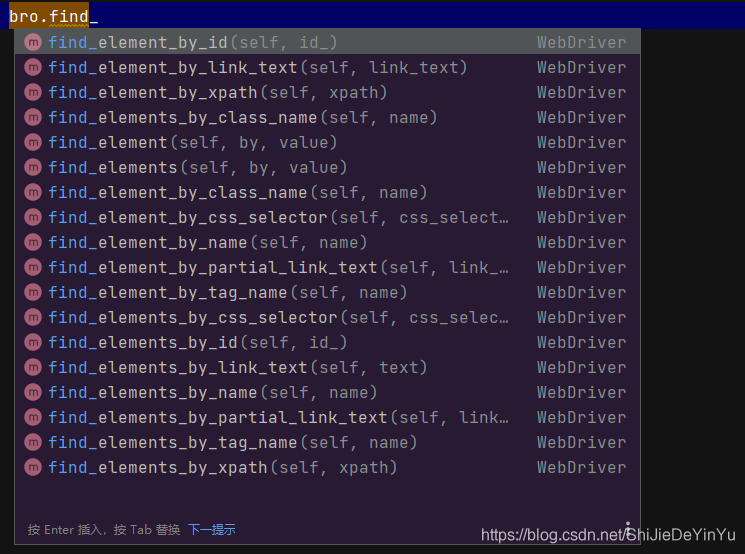
# 使用 class 属性定位到 “x” 符号
btn = bro.find_element_by_class_name('desktop-guide-close')
# 模拟鼠标点击
btn.click()
注意:
如果报错,很有可能是还没加载完成,可以使用 time.sleep() 让页面完成加载
接下来我们就看到页面来到我们熟悉的页面
那么我们要怎么把我们想要翻译的文字输入到文本框中呢?
还是先定位到文本框的位置,再输入文字(使用 send_keys() 方法),点击翻译
# 定位到文本框
translate_input = bro.find_element_by_id('baidu_translate_input')
# 传入文字
translate_input.send_keys("奥特曼")
# 等待两秒
sleep(2)
结果如图
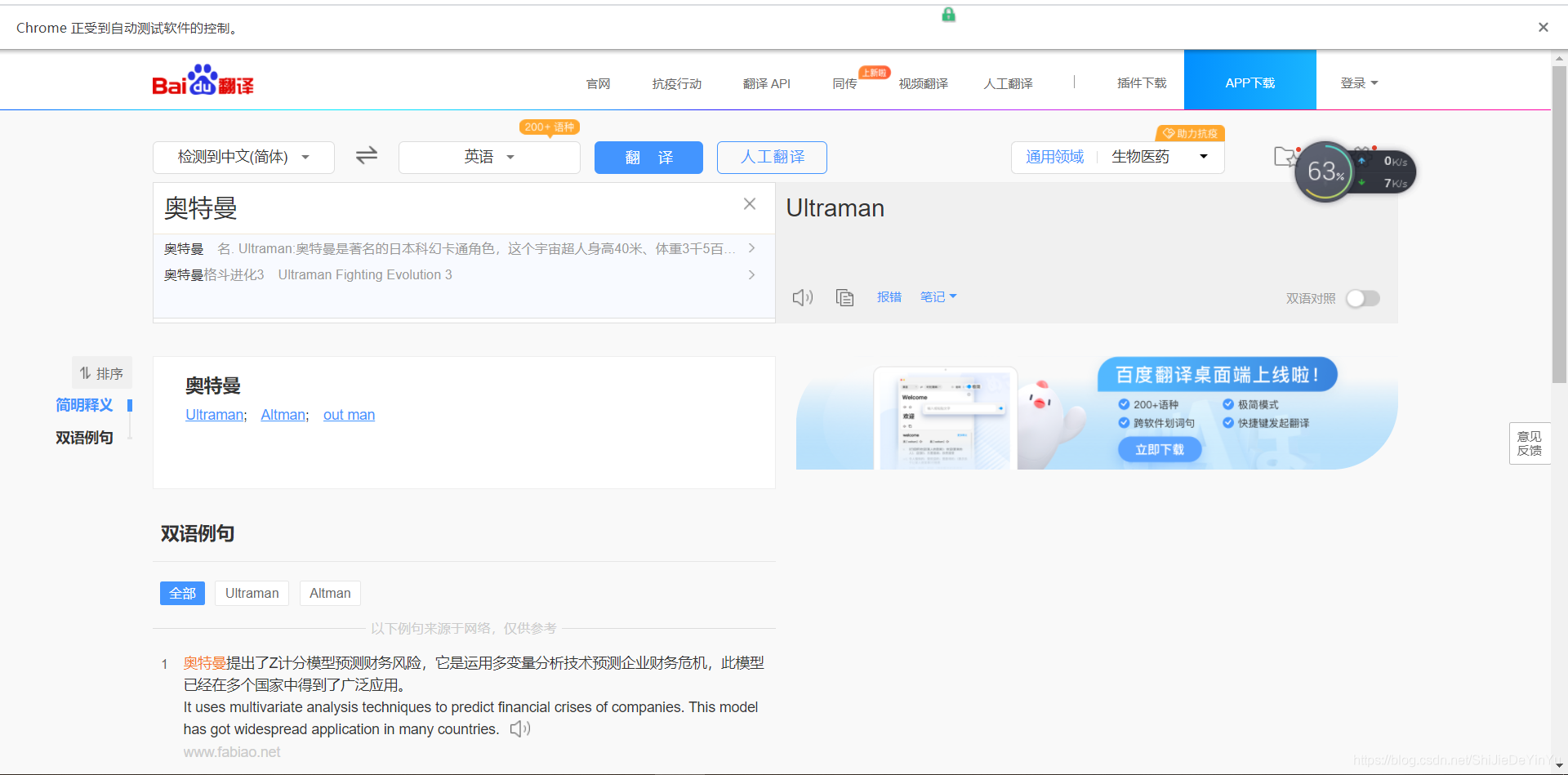
因为是动态加载的数据,所以我们不需要点击 “ 翻译 ”,结果就会自动出现。如果需要点击,我们也可以先定位按键的位置,再模拟点击。
那么我们要如何获取翻译的结果呢?
我们知道动态加载的数据需要找到相应的 API,那么现在我们需要吗?答案是不需要,我们只需要对现在的页面进行 xpath 解析就行。
代码如下:
from lxml import etree
……
# 获取此时的页面源码
page = bro.page_source
# xpath 解析
tree = etree.HTML(page)
content = tree.xpath('//*[@id="main-outer"]/div/div/div[1]/div[2]/div[1]/div[2]/div/div/div[1]/p[2]/span/text()')
print(content)
bro.quit()
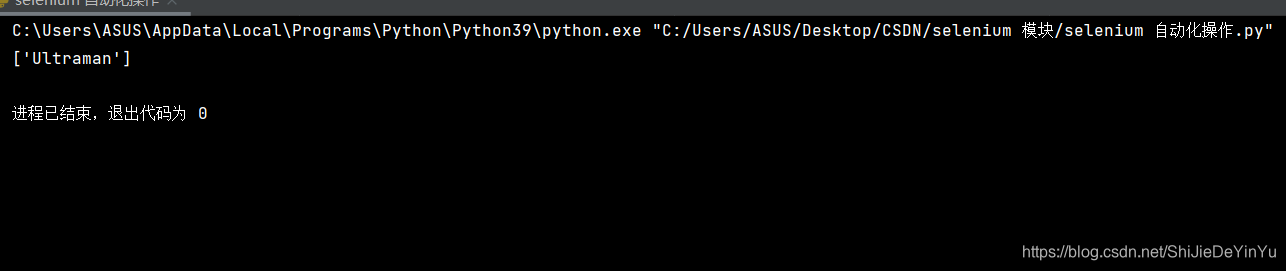
结果如下