模拟登录人人网
前面我们学习了使用第三方平台实现验证码的识别,那现在就让我们来用验证码的识别实现人人网的登录。
首先我们先到人人网的登录页面去踩点。
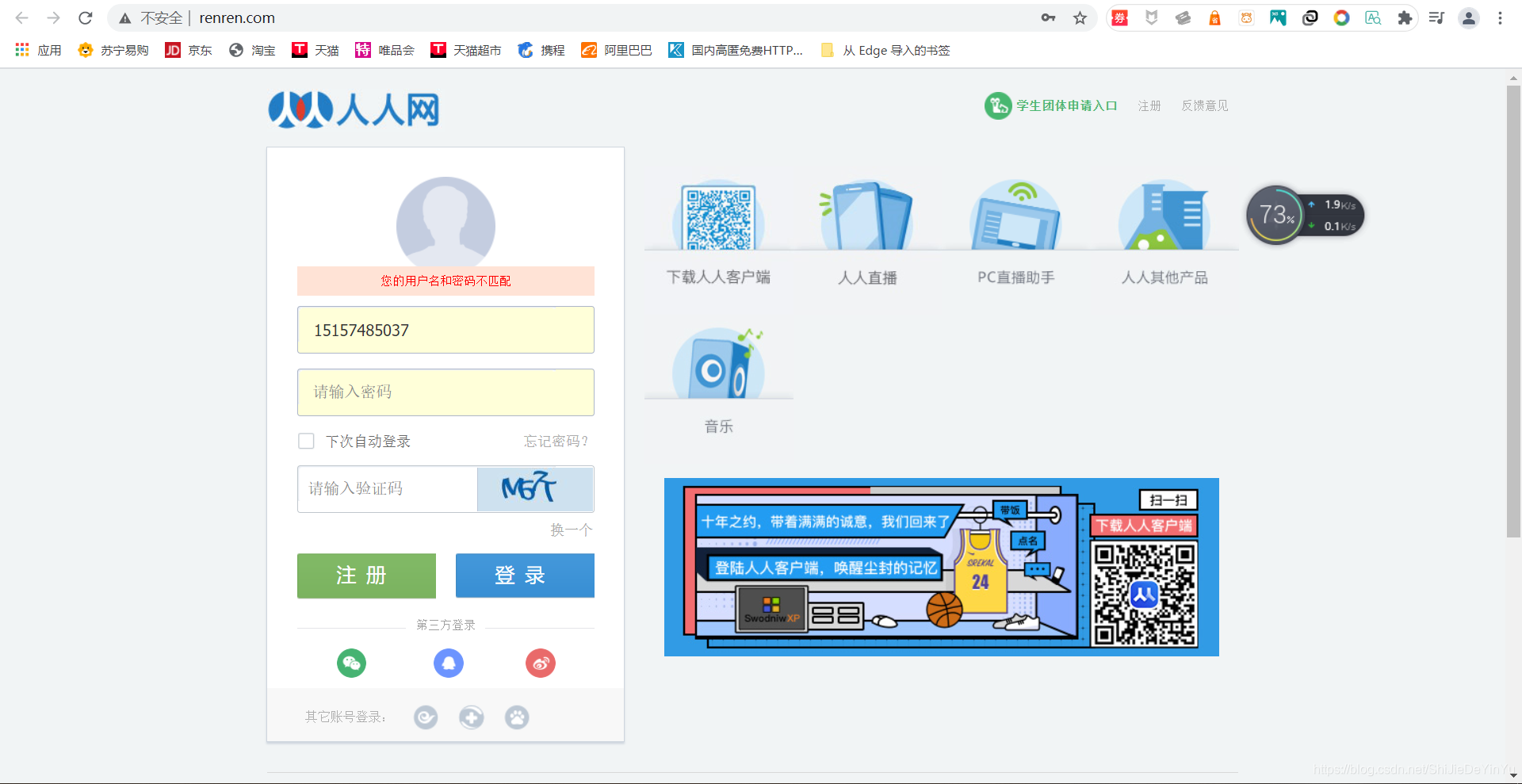
人人网登录在三次失败后需要输入验证码,那我们现在需要做的就是通过数据解析将验证码保存到本地(为了更好的使用第三方验证码识别平台)。
有了验证码之后,我们又要怎么通过爬虫实现登录呢?首先我们打开抓包工具,看看登陆时会发生什么。
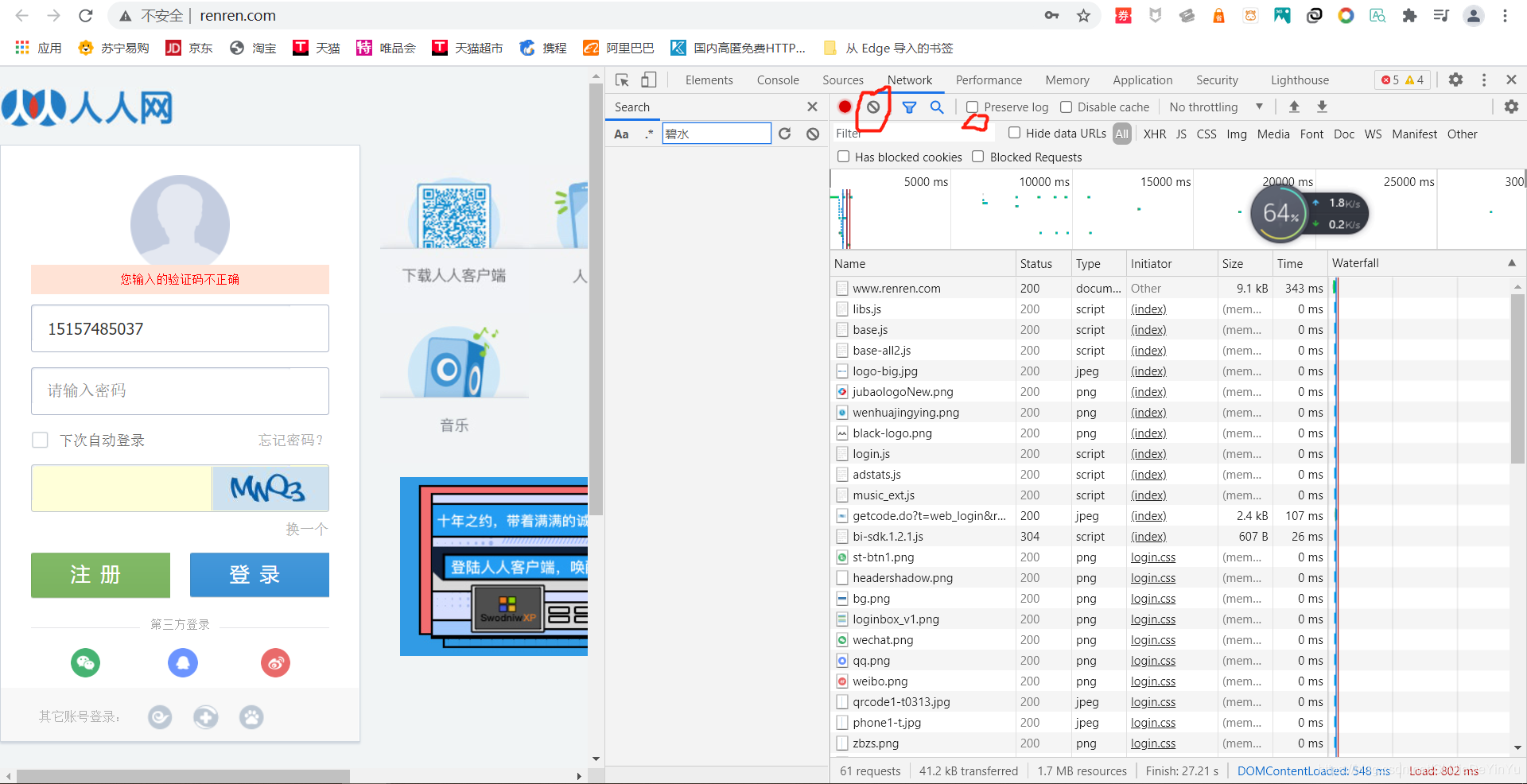
首先我们先点击那个禁止符号的符号,将数据清空,然后再点击 “ preserve log ”,然后我们再实现登录。
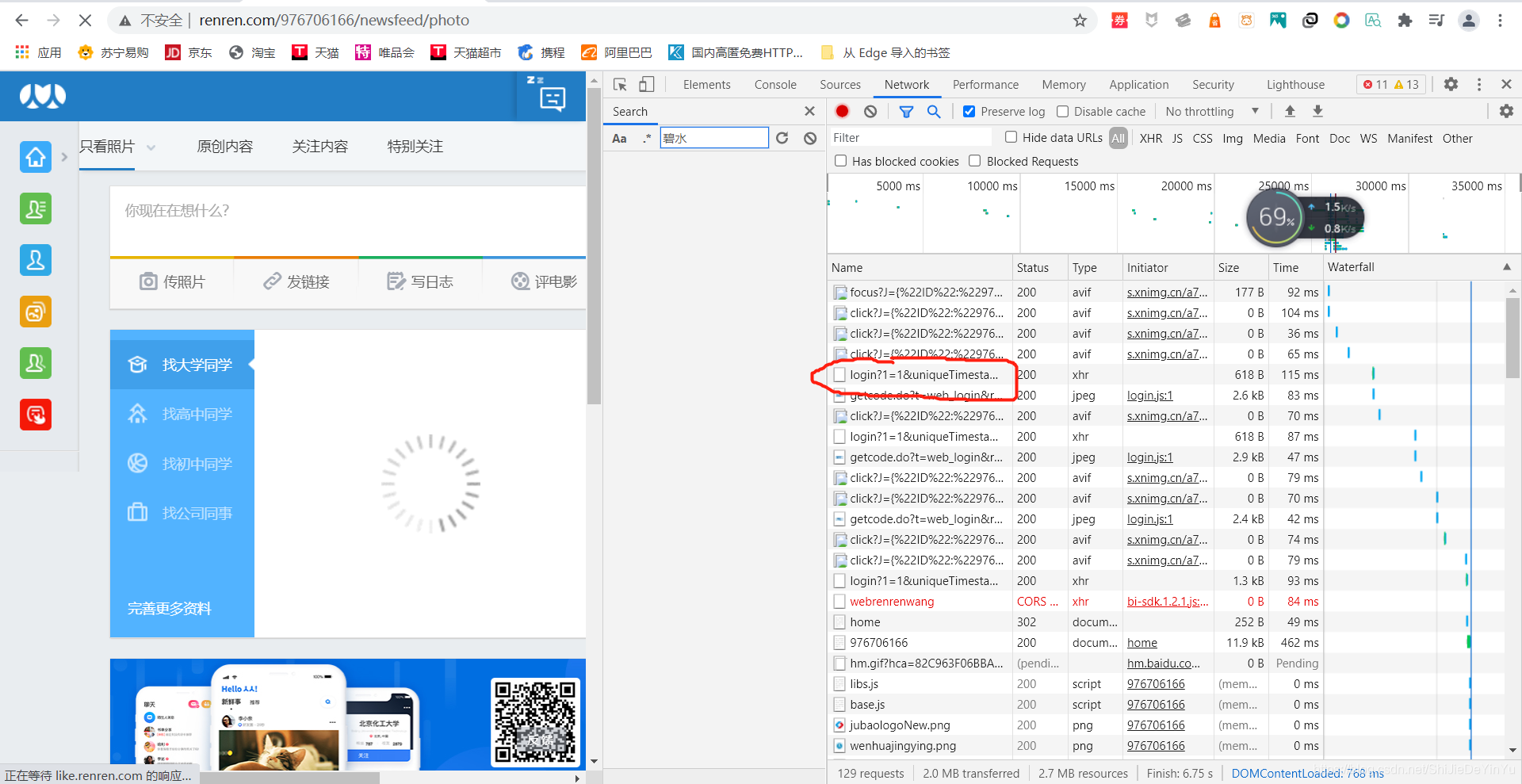
我们发现这里有一个 login 的文件,我们点开它。
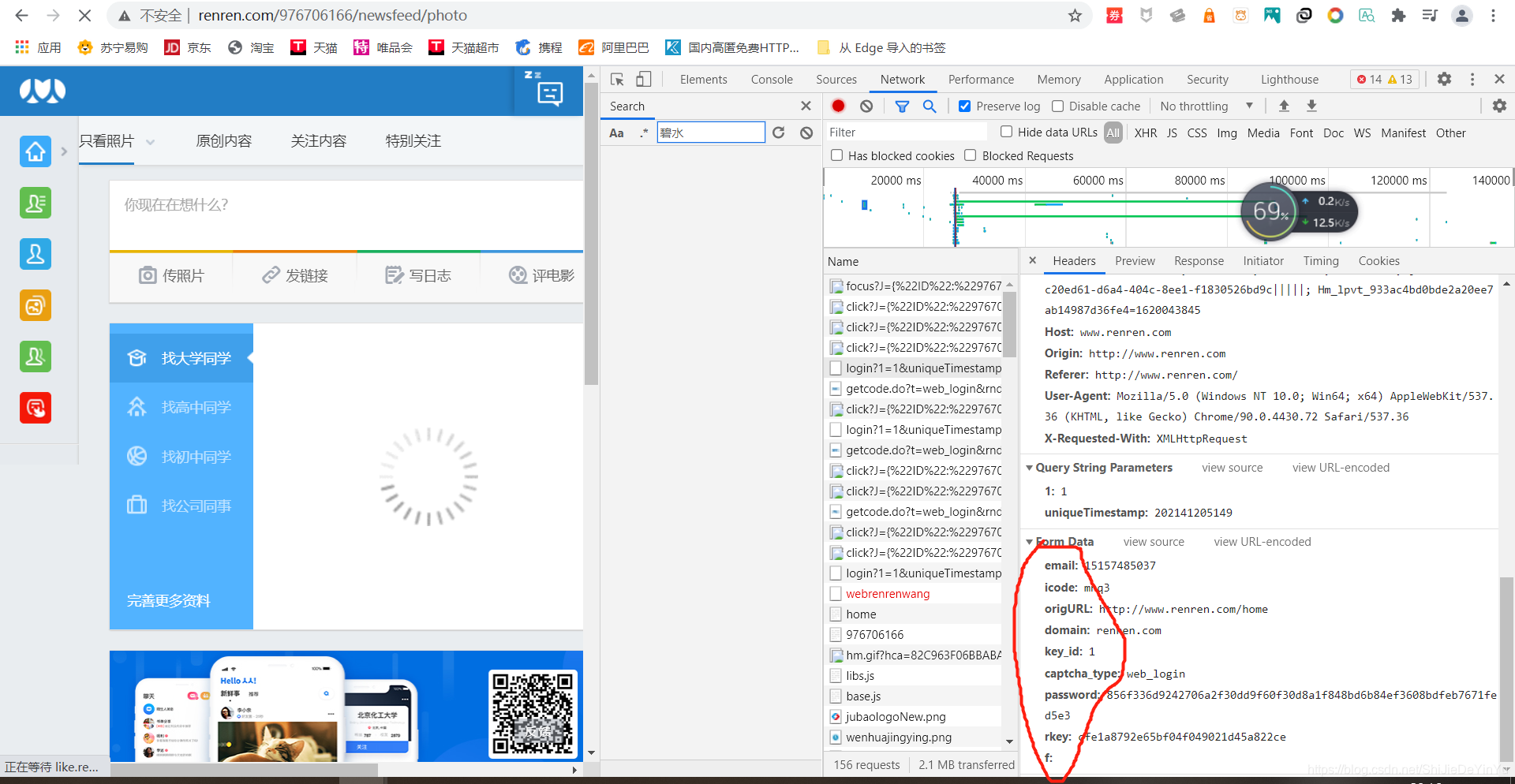
我们发现这个文件的 data 一栏里的 icode 是我们输入的验证码,那么我们就有理由怀疑这一栏需要动态改变的就是 icode 这一栏,这就是说我们前面保存的验证码在这里就有用武之地。
分析结束,就开始写代码了。
import requests
from lxml import etree
import base64
import json
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd,"typeid":typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
return ""
if __name__ == "__main__":
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定url
url = "http://www.renren.com/"
# 获取源码
page_text = requests.get(url = url, headers = header).text
# xpath 解析
tree = etree.HTML(page_text)
src = tree.xpath('//*[@id="verifyPic_login"]/@src')[0] # 验证码网址
# 保存验证码
photo = requests.get(url = src, headers = header).content
with open("./验证码.jpg", "wb") as fp:
fp.write(photo)
img_path = "C:\\Users\\ASUS\\Desktop\\CSDN\\验证码识别\\验证码.jpg"
result = base64_api(uname='账号', pwd='密码', img=img_path, typeid=3)
print(result)
# 登录网址
url = "http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=20214120314"
data = {
"email": "15157485037",
"icode": result,
"origURL": "http://www.renren.com/home",
"domain": "renren.com",
"key_id": "1",
"captcha_type": "web_login",
"password": "8a62222be07c2cf68e8d68f4617fe01d7dbc488427d0bc61666ab8a6e56e94f0",
"rkey": "07a9f1810ecf9b507634a45447a628e7",
"f": "http%3A%2F%2Fwww.renren.com%2F976706166%2Fprofile"
}
# 模拟登录
response = requests.post(url = url, headers = header, data = data)
# 判断登录状态。 200 说明登录成功
print(response.status_code)
我们看一下运行结果
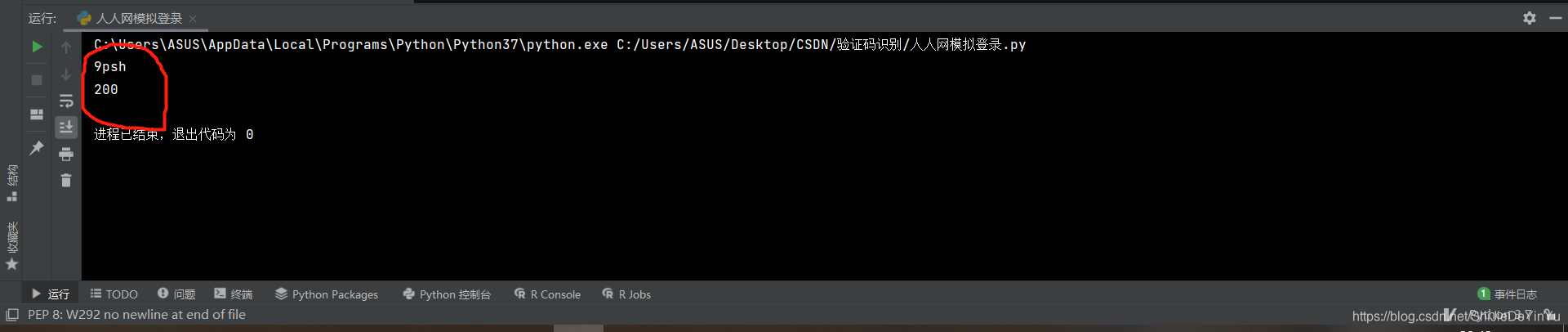
说明登录成功。
注意:
我们一般用这种方法判断是否登录,其实也可以保存页面来判断,但有一些网站登录成功后返回的并非是网页而是 json 串,所以我们通常用 status code 来判断是否成功,200 表示和网页连接成功。



