验证码识别
我们使用爬虫时很有可能需要登录,而现在的平台登陆时都需要验证码才能完成登录,所以我们使用爬虫模拟登录时验证码是必须要跨过的坎。一般情况下,我们使用第三方平台实现验证码的识别。
所以我在这里介绍一个识别验证码的平台——图鉴(比较常见的有超级鹰,反正其实这些平台注册、使用流程都差不多)。
首先我们打开图鉴的网址 “ http://www.ttshitu.com/ ”,点击注册


登录成功后,我们首先看一下“价格”,其实也可以在注册帐号前看一看价格,再决定是否注册。在登陆后,因为识别验证码需要登录,所以我们在使用前要确定自己的帐号里是否还有余额。我觉得这些平台的充值还是挺人性化的,,是允许我们在平台上充值一块五毛的。
我们的账号里有钱了,然后再打开开发文档。因为我们使用的是python,所以我们选择python的开发文档

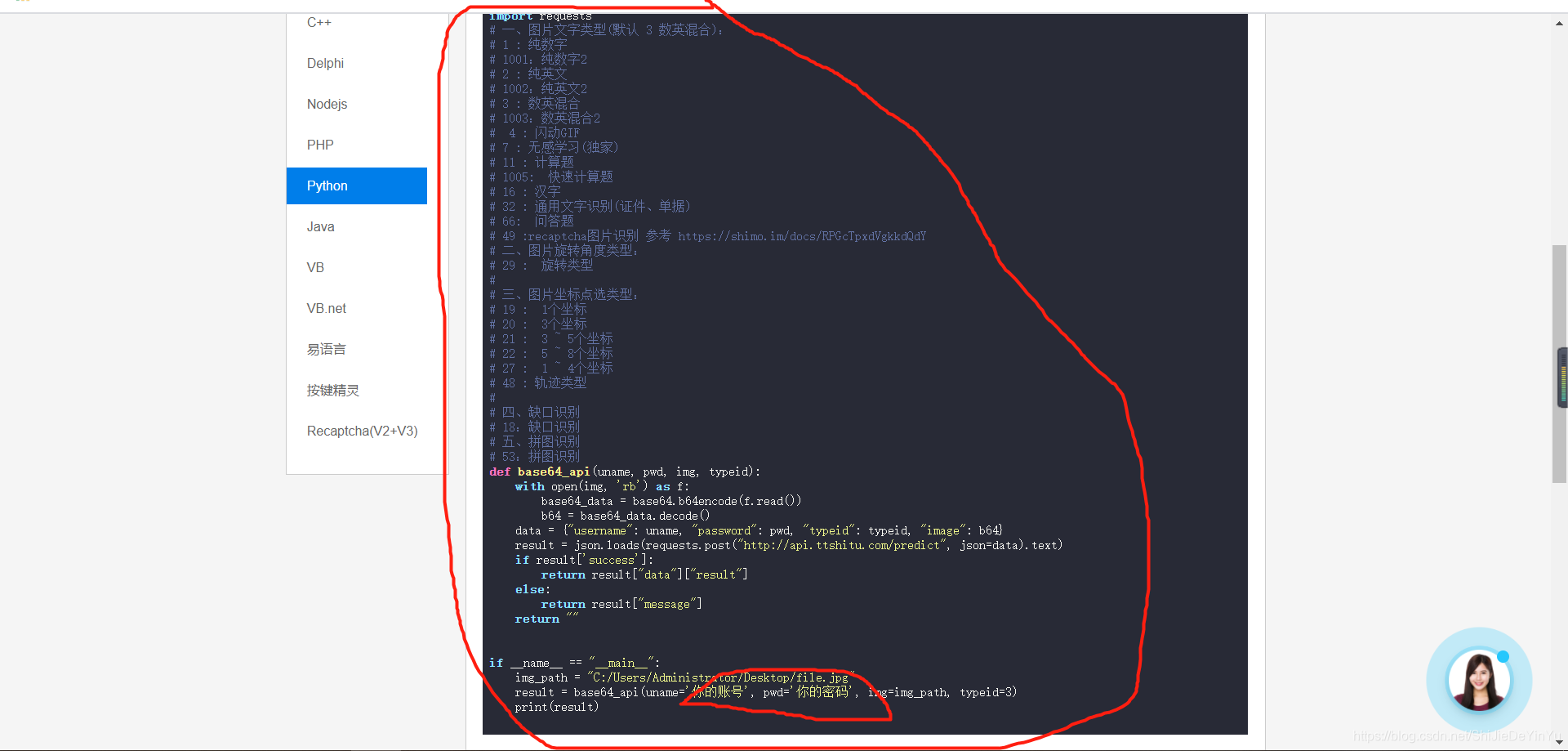
将第一个脚本复制下来,用 IDLE 打开,我们看到代码部分的注释是提示我们 typeid 的参数选择。
在我们开始分析代码,代码自定义了一个函数,这个函数我们不需要看懂,重要的是下面的主程序,我们需要改的是我上面圈起来的部分,也就是运行程序时需要输入验证码的保存路径(也就是说我们需要将验证码先保存到本机),需要在程序中输入我们图鉴的账号和密码。
我这里有一张验证码,现在就让我们试试图鉴的脚本

代码如下:
import base64
import json
import requests
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
return ""
if __name__ == "__main__":
img_path = "C:\\Users\\ASUS\\Desktop\\验证码.jpg" # 这里填写验证码的路径
result = base64_api(uname='账号', pwd='密码', img=img_path, typeid=3)
# 因为验证码里有数字和中文,我们 typeid 选择 3
print(result)
结果如下
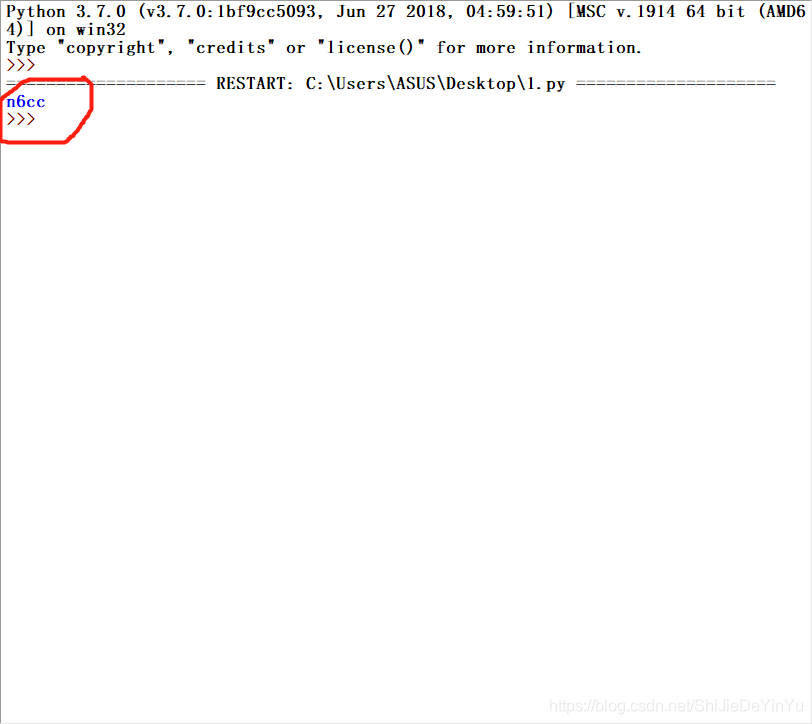
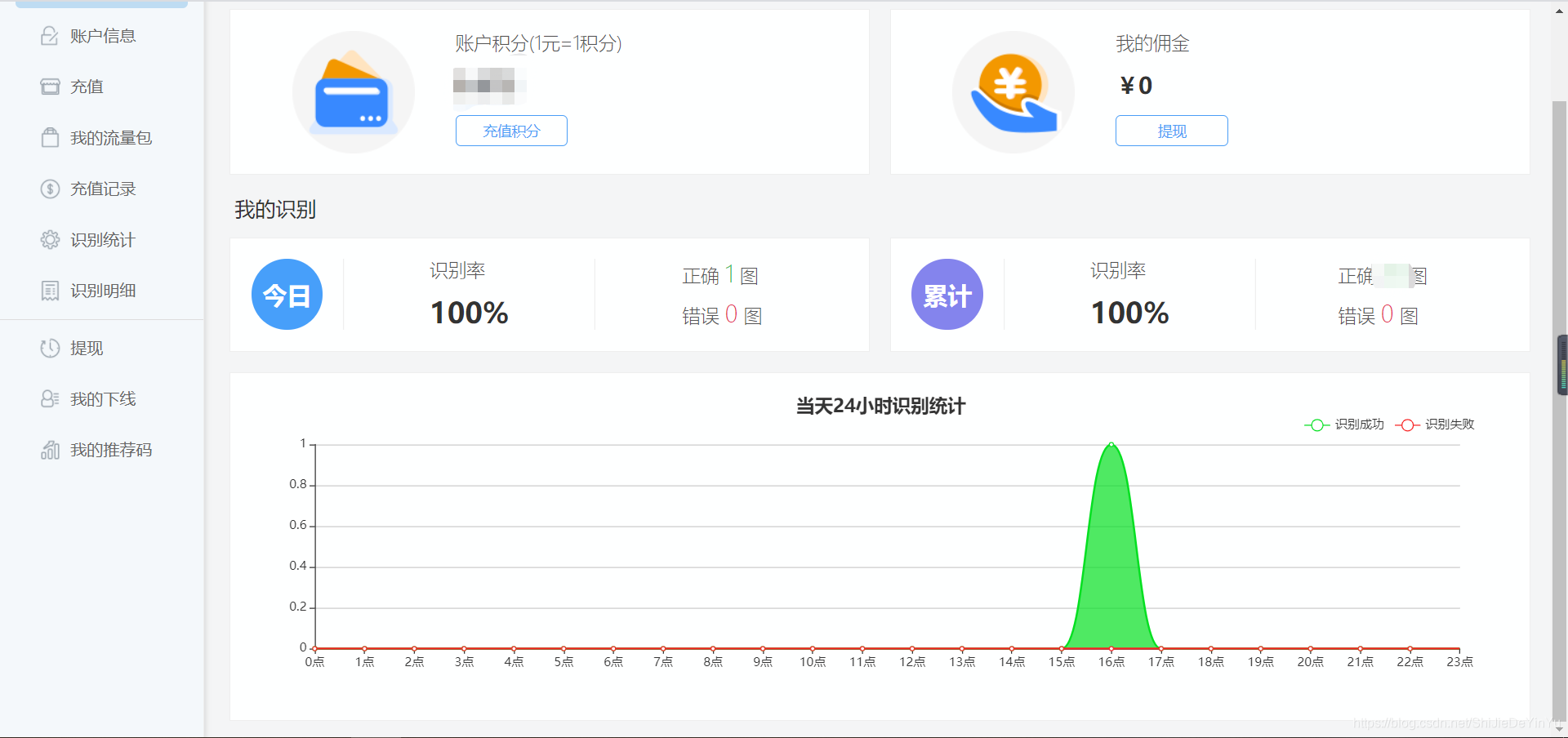
然后我们回到图鉴网站个人中心看看,结果如下
注意:
验证码的识别正确率并不是 100% 的,有时需要多次识别



