什么?我怎么又讲爬取图片?拜托,这可是 4k 图片,清晰度杠杠的。再说,爬取糗图算什么本事,做人要爬取的肯定是妹子图片,而且是 4k 的妹子图片,是不是很激动?放心,这次不晃你。
源码分析
首先让我们打开网页,好好欣赏一下美丽的妹子……哦不,我是说,好好的欣赏一下优美的网页源码。网址如下:https://pic.netbian.com/4kmeinv/
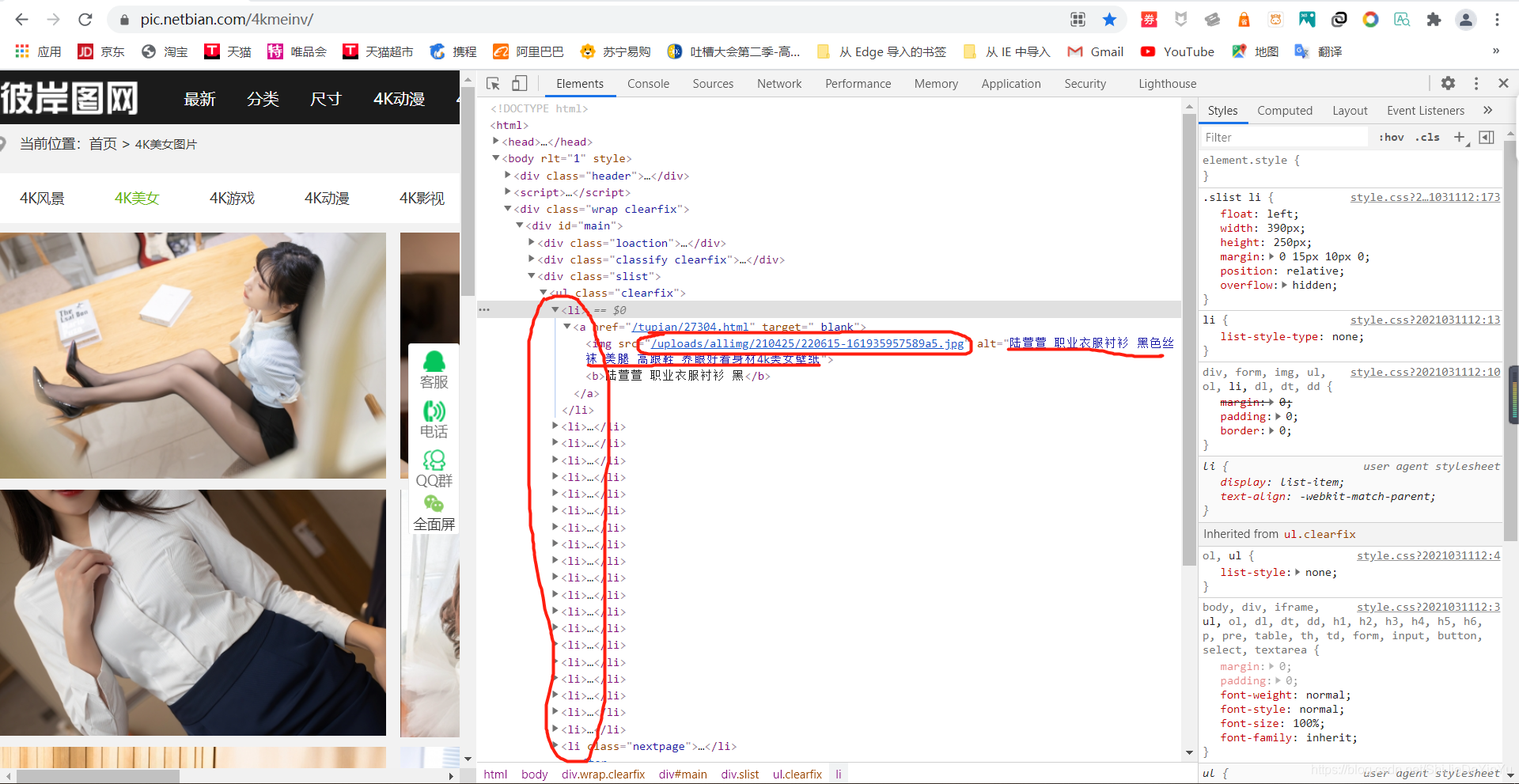
看,是不是优美的妹子?……额咳咳,我是说优美的源码。
很好,我们注意一下定位到的源码数据,也就是我圈的地方,这里有图片的网址和图片的标题。我们就把原标题作为我们下载后的标题。注意,这里的网址没有域名,是需要我们自己加的,也就是 “https://pic.netbian.com”。
欧克,是不是迫不及待了,让我们和小姐姐更进一步吧,咳咳,我是说,不说了,你懂的!
文字编译
import requests
from lxml import etree
if __name__ == "__main__":
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定网址
url = "https://pic.netbian.com/4kmeinv/"
# 获取源码
response = requests.get(url = url, headers = header).text
# xpath 解析
tree = etree.HTML(response)
new_url_list = tree.xpath('//div[@class="slist"]/ul/li/a/img/@src')
title_list = tree.xpath('//div[@class="slist"]/ul/li/a/img/@alt')
# 测试
print(new_url_ist)
print()
print(title_list)
print(len(title_list) == len(new_url_list))
结果测试的时候发现不对了,我们的标题全都变成乱码了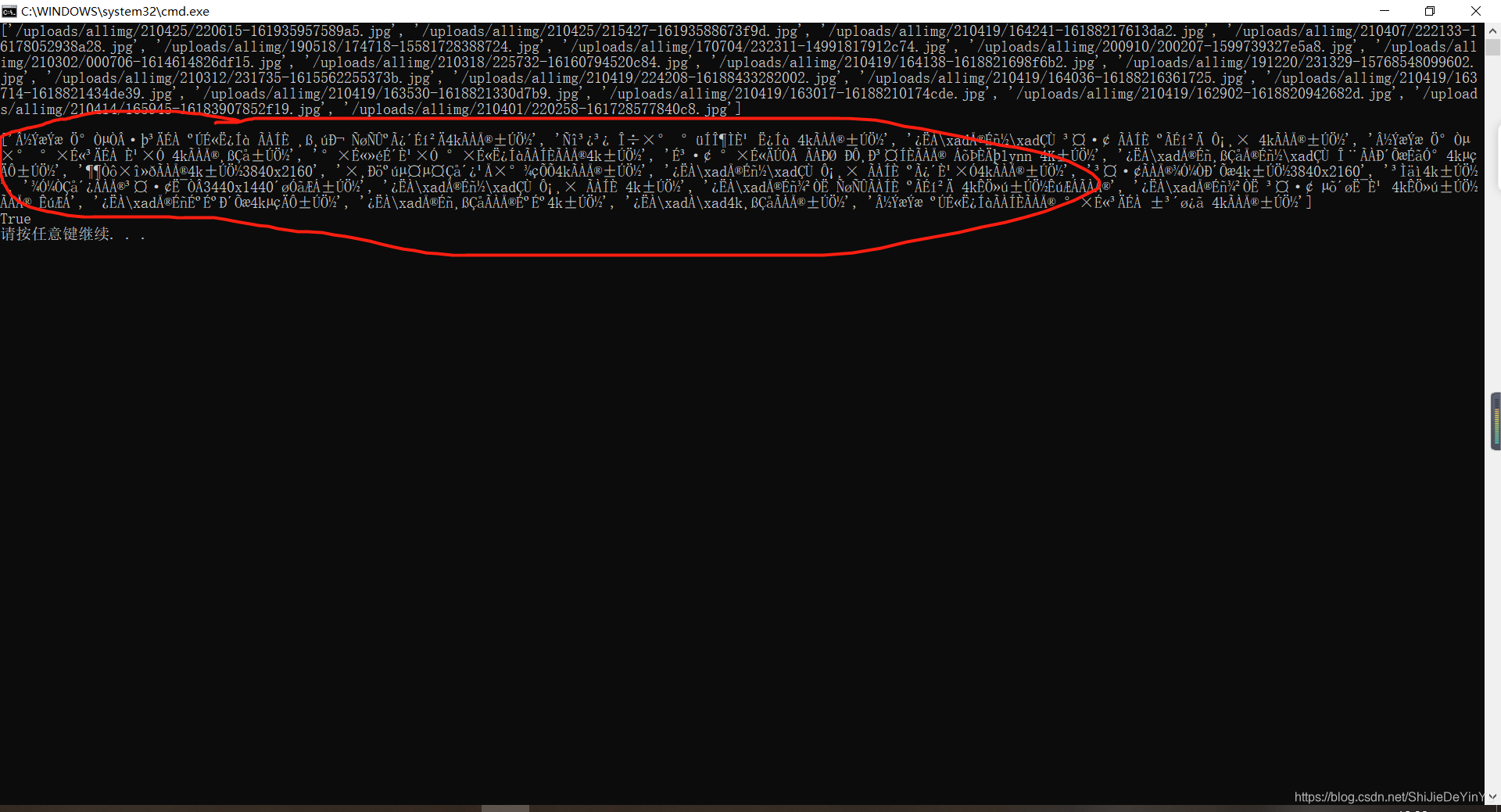
再一看,哦,我们太激动忘记编译了,赶紧编译一下。
import requests
from lxml import etree
if __name__ == "__main__":
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定网址
url = "https://pic.netbian.com/4kmeinv/"
# 获取源码
response = requests.get(url = url, headers = header)
response.encode = "utf-8"
response = response.text
# xpath 解析
tree = etree.HTML(response)
new_url_list = tree.xpath('//div[@class="slist"]/ul/li/a/img/@src')
title_list = tree.xpath('//div[@class="slist"]/ul/li/a/img/@alt')
# 测试
print(new_url_list)
print()
print(title_list)
print(len(title_list) == len(new_url_list))
这回总该可以了吧,再一看,怎么回事,还是乱码。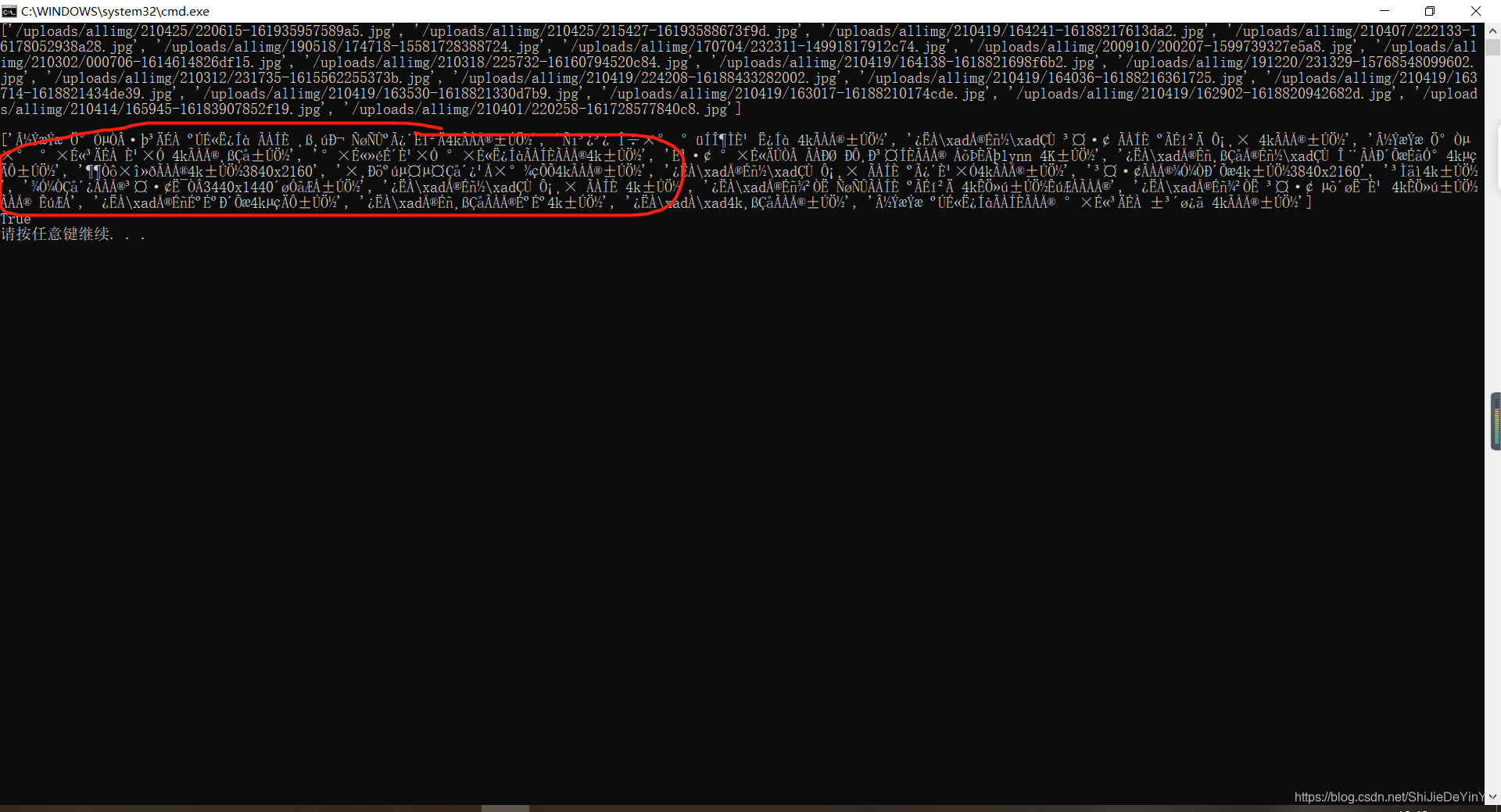
这是为什么?难道说所谓的 4k 美女图片只可远观不可亵玩吗?我不相信,赶紧去研究研究。正所谓,“X 是第一生产力”,我很快就研究出结果了,一般情况下,如果源码里有中文,我们可以有两种办法。一种是我们用的方法,另一种方法如下:
response = response.encode("iso-8859-1").decode("gbk")
我们再试一次
import requests
from lxml import etree
if __name__ == "__main__":
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定网址
url = "https://pic.netbian.com/4kmeinv/"
# 获取源码
response = requests.get(url = url, headers = header).text
response = response.encode("iso-8859-1").decode("gbk")
# xpath 解析
tree = etree.HTML(response)
new_url_list = tree.xpath('//div[@class="slist"]/ul/li/a/img/@src')
title_list = tree.xpath('//div[@class="slist"]/ul/li/a/img/@alt')
# 测试
print(new_url_list)
print()
print(title_list)
print(len(title_list) == len(new_url_list))
测试一下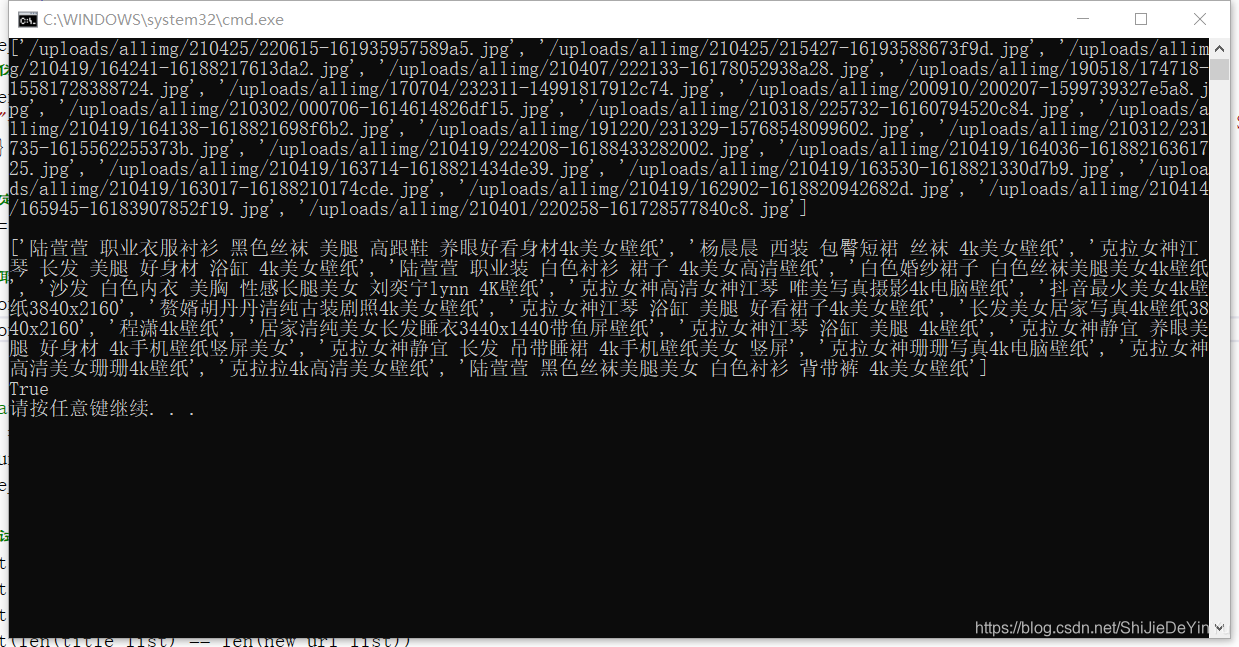
欧克,是中文了,接着可以爬取4k妹子图片了。
爬取妹子图
import requests
from lxml import etree
import os
if __name__ == "__main__":
# 创建文件夹
if not os.path.exists("C:\\Users\\ASUS\\Desktop\\CSDN\\数据解析\\xpath\\爬取 4k 图片\\4k图片"):
os.mkdir("C:\\Users\\ASUS\\Desktop\\CSDN\\数据解析\\xpath\\爬取 4k 图片\\4k图片")
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
for index in range(1, 4): # 翻三页
# 指定网址
if index == 1:
url = "https://pic.netbian.com/4kmeinv/"
else:
url = "https://pic.netbian.com/4kmeinv/index_%s.html" % index
# 获取源码
response = requests.get(url = url, headers = header).text
response = response.encode("iso-8859-1").decode("gbk")
# xpath 解析
tree = etree.HTML(response)
new_url_list = tree.xpath('//div[@class="slist"]/ul/li/a/img/@src')
title_list = tree.xpath('//div[@class="slist"]/ul/li/a/img/@alt')
# 测试
# print(new_url_list)
# print()
# print(title_list)
# print(len(title_list) == len(new_url_list))
num = len(title_list)
for i in range(num):
new_url = "https://pic.netbian.com" + new_url_list[i]
title = title_list[i]
photo = requests.get(url = new_url, headers = header).content
# 保存
with open("C:\\Users\\ASUS\\Desktop\\CSDN\\数据解析\\xpath\\爬取 4k 图片\\4k图片\\" + title + ".jpg", "wb") as fp:
fp.write(photo)
print(title, "下载完成!!!")
print("over!!!")
完成后,我们激动地打开图片,滚烫的热血突然就冷下来了,不是说是4k高清图吗,怎么不仅是缩略图,而且画质还不行。

别着急,这可不是我骗你,是网址留了一手。
爬取真正的4k妹子图
现在我们知道了网址源码里的网址是缩略图,那么我们怎么办呢?很简单,我们点击一下会怎样?
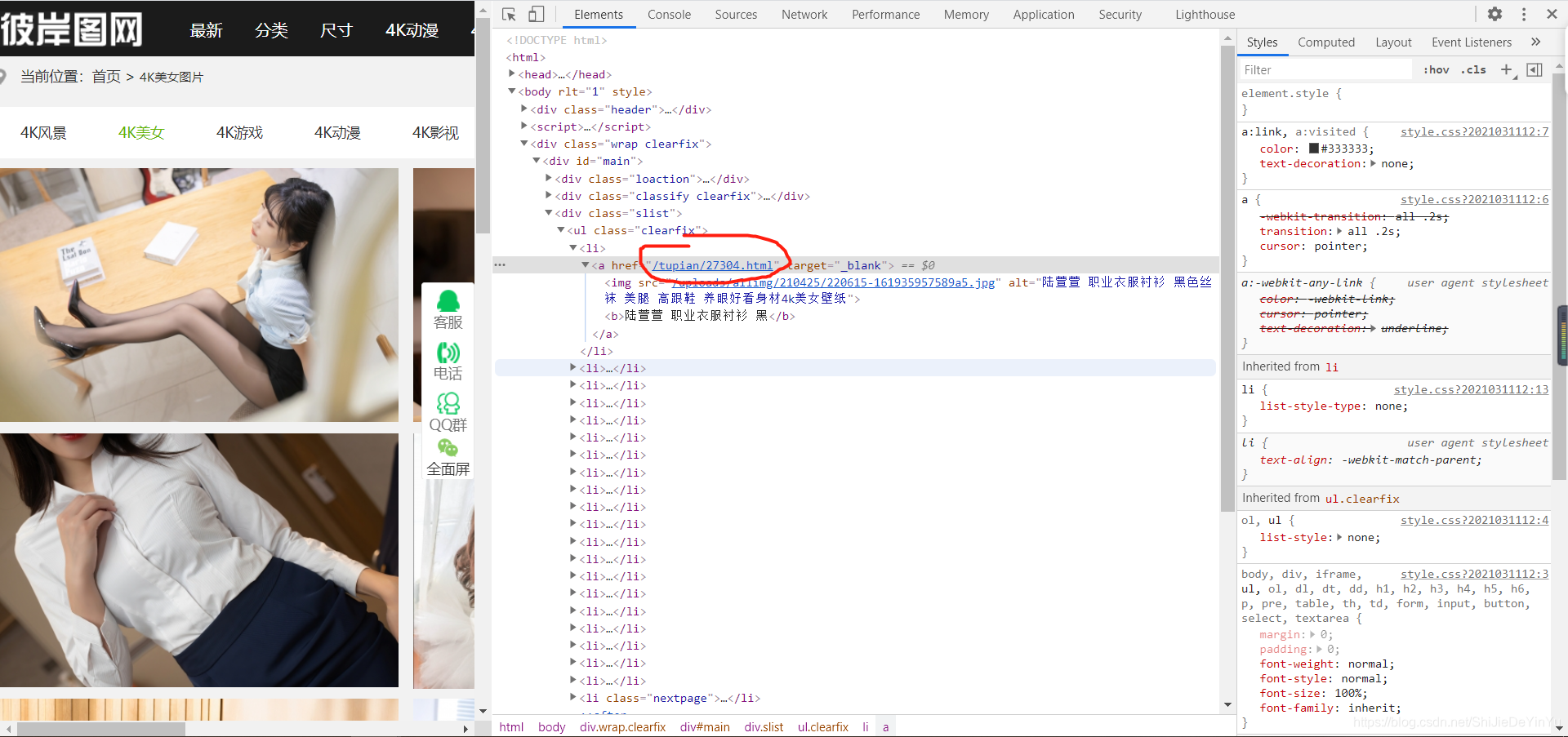
然后我们来到了下载页面。
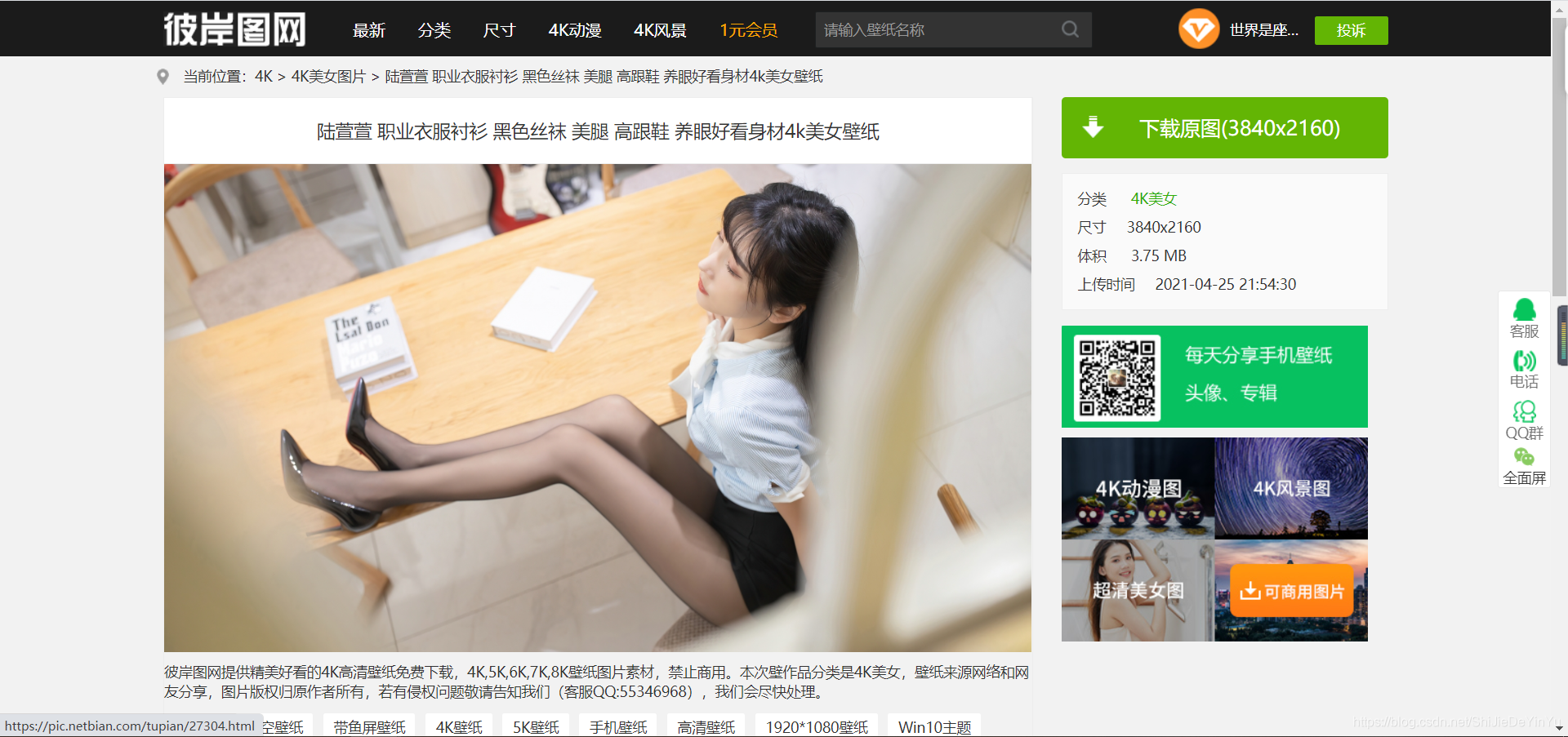
现在我们没有任何办法,那就试着看看现在的网页源码好了。
结果我们发现了两个图片的地址,点开,发现一个是缩略图,一个是4k妹子图。如图。
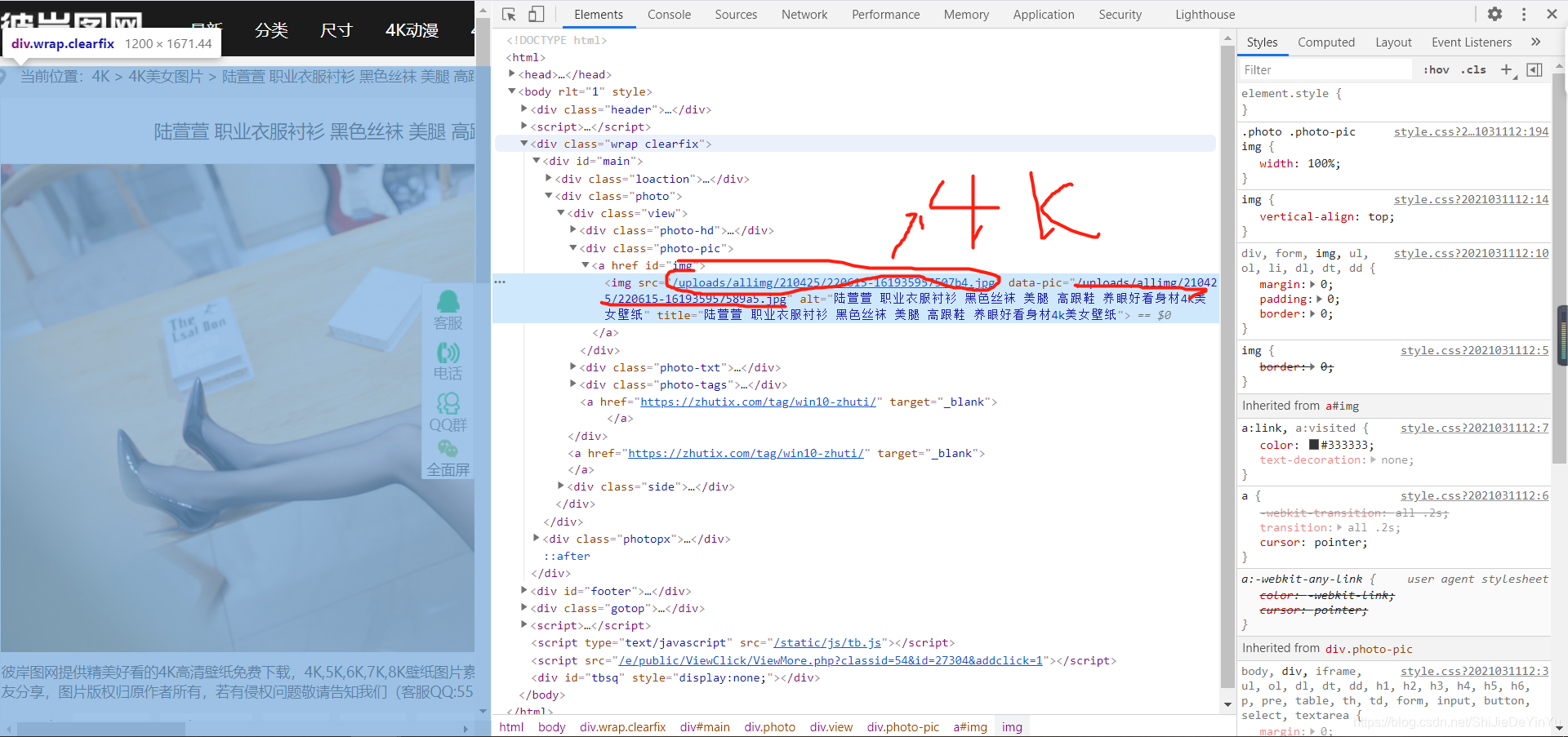
是不是又感觉热血沸腾了?嘿嘿
闲话少说,赶紧改进代码
import requests
from lxml import etree
import os
if __name__ == "__main__":
# 创建文件夹
if not os.path.exists("C:\\Users\\ASUS\\Desktop\\CSDN\\数据解析\\xpath\\爬取 4k 图片\\4k图片(4k)"):
os.mkdir("C:\\Users\\ASUS\\Desktop\\CSDN\\数据解析\\xpath\\爬取 4k 图片\\4k图片(4k)")
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
for index in range(1, 4): # 翻三页
# 指定网址
if index == 1:
url = "https://pic.netbian.com/4kmeinv/"
else:
url = "https://pic.netbian.com/4kmeinv/index_%s.html" % index
# 获取源码
response = requests.get(url = url, headers = header).text
response = response.encode("iso-8859-1").decode("gbk")
# xpath 解析
tree = etree.HTML(response)
# li 标签所在的列表,下载页面的网址在 li 标签内
li_list = tree.xpath('//div[@class="slist"]/ul/li')
for li in li_list:
# 获取下载页面的网址
new_url = "https://pic.netbian.com" + li.xpath('a/@href')[0]
# 获取下载页面的网页源码
new_response = requests.get(url = new_url, headers = header).text
new_response = new_response.encode("iso-8859-1").decode("gbk") # 编译文字
# xpath 解析
new_tree = etree.HTML(new_response)
# 下载的地址
src = "https://pic.netbian.com" + new_tree.xpath('//*[@id="img"]/img/@src')[0]
# 图片标题
title = new_tree.xpath('//*[@id="img"]/img/@title')[0]
# 获取图片
photo = requests.get(url = src, headers = header).content
# 保存
with open("C:\\Users\\ASUS\\Desktop\\CSDN\\数据解析\\xpath\\爬取 4k 图片\\4k图片(4k)\\" + title + ".jpg", "wb") as fp:
fp.write(photo)
print(title, "下载成功!!!")
print("over!!!")
运行结束了,赶紧打开照片看一看,很好,这次真的是4k妹子图片了。




