xpah 的语法认识
闲话少说,直接上图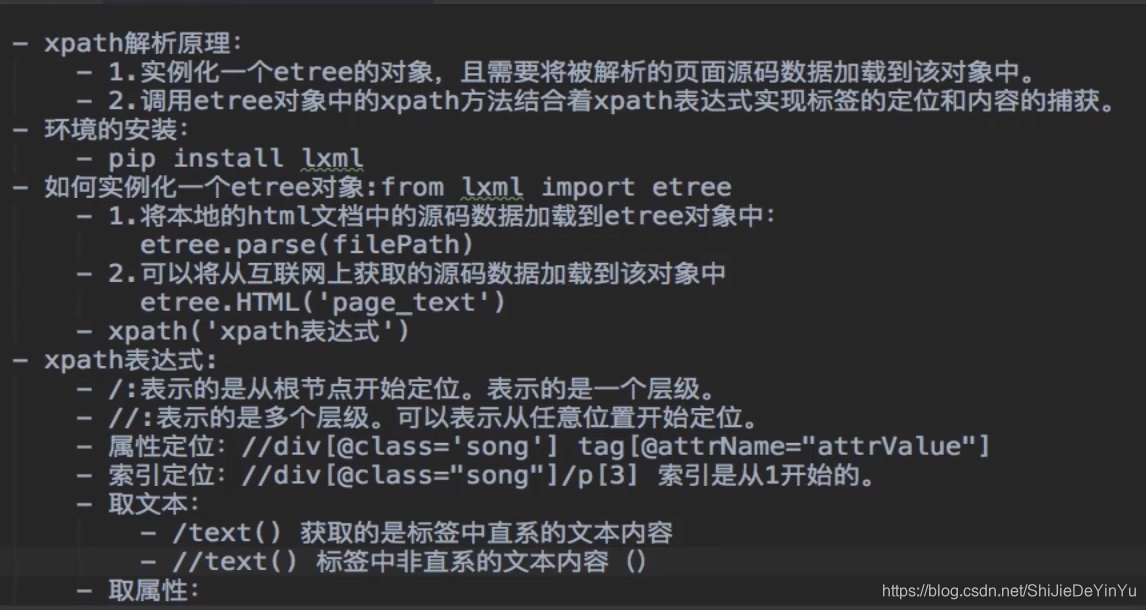
xpath 爬取图片
代码如下
import requests
from lxml import etree
import os
if __name__ == "__main__":
# 创建文件夹
if not os.path.exists("./糗图(xpath)"):
os.mkdir("./糗图(xpath)")
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
for index in range(1, 3): # 翻两页
# 指定url
url = "https://www.qiushibaike.com/imgrank/page/%s/" % str(index)
# 获取源码
response = requests.get(url = url, headers = header).text
# xpath 解析
tree = etree.HTML(response)
src_list = tree.xpath('//div[@class="thumb"]/a/img/@src')
# print(src_list) # 测试定位是否有错误
for src in src_list:
title = src.split("/")[-1]
# 新的url
new_url = "https:" + src
# 获取图片
photo = requests.get(url =new_url, headers = header).content
# 存储
with open("./糗图(xpath)/" + title, "wb") as fp:
fp.write(photo)
print(title, "下载成功!!!")
print("over!!!")
xpath 爬取三国演义
import requests
from lxml import etree
if __name__ == "__main__":
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定 url
url = "http://sanguo.5000yan.com/"
# 获取源码
response = requests.get(url = url, headers =header)
response.encoding = "utf-8" # 编译源码,防止乱码
response = response.text
# xpath 解析
tree = etree.HTML(response)
src_list = tree.xpath('//div[@class="sidamingzhu-list-mulu"]//li[@class="menu-item"]/a/@href')
# print(src_list) # 测试是否正确
title_list = tree.xpath('//div[@class="sidamingzhu-list-mulu"]//li[@class="menu-item"]/a/text()')
# print(title_list) # 测试是否正确
for index in range(len(src_list)):
# 指定新的url
new_url = src_list[index]
title = title_list[index]
# 获取新的网页源码
page_text = requests.get(url = new_url, headers = header)
page_text.encoding = "utf-8"
page_text = page_text.text
# xpath 解析
new_tree = etree.HTML(page_text)
page = new_tree.xpath('//section[@class="section-body"]//div[@class="grap"]//text()')
# 存储
with open("C:\\Users\\ASUS\\Desktop\\CSDN\\数据解析\\xpath\\三国演义.txt", "a", encoding = "utf-8") as fp:
fp.write("\n\n" + title + "\n\n")
for i in page:
fp.write(i)
print(title, "下载成功!!!")
print("over!!!")



