药监局爬取
是不是在看到 “ 药监局 ” 这三个字的时候,突然想到爬虫可能会进局子的事实? 说到局子,我突然想到另一件事,因为前面写的是很基础的代码,没有代理池,所以在写的时候,特别是爬取翻页的时候,尽量减少爬取的页数,不然,额,后果自负。
开个玩笑,没什么大问题的,就是很有可能自己的 IP 会被对面拉入黑名单(目前学的代码而言)
欧克,言归正传,让我们回到药监局的爬取上吧。如果不出意外的话,这是 requests 模块的最后练习了,结束之后就是激动人心的数据解析了。
先说说药监局网站,我不清楚是因为我用的是学校局域网的原因,还是药监局网站本身的数据维护更新原因,我这边晚上八点半之后就打开不了药监局网站了。
闲话少说(其实说了很多),我们先打开药监局网站(http://scxk.nmpa.gov.cn:81/xk/),一探究竟。
当我们随便点击一家企业时,得到的界面如下:
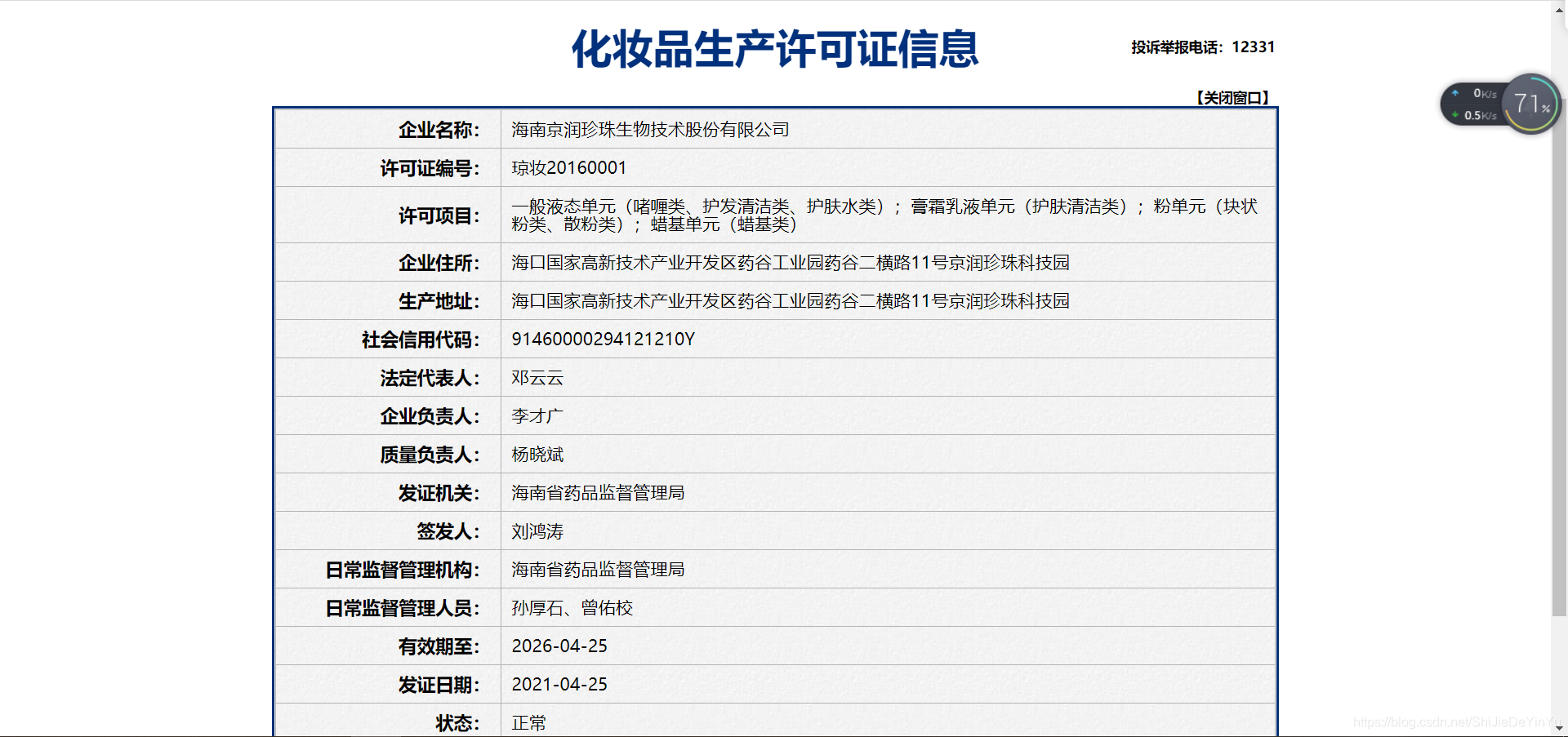
而这些企业具体信息是我们今天要爬取的对象数据。
首先我们来爬取药监局的首页数据。
代码如下:
import requests
if __name__ == "__main__":
# UA 伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定 URL
url = "http://scxk.nmpa.gov.cn:81/xk/"
# 发送请求
page_text = requests.get(url, headers = header).text
# 保存
with open("./药监局.html", "w", encoding = "utf-8") as fp:
fp.write(page_text)
print("over!!!")
然后我们打开保存的文件一看。
唉,为什么,明明已经加载完成了,但我们看不到任何企业的信息?
别着急,让我们现在回到药监局的首页,打开抓包工具的 “ Network ” 分析一波(当然其实我们可以使用 数据解析 解决这个问题,但实际上我们还没学不是吗?)。欧克,回到抓包工具,点击 response。
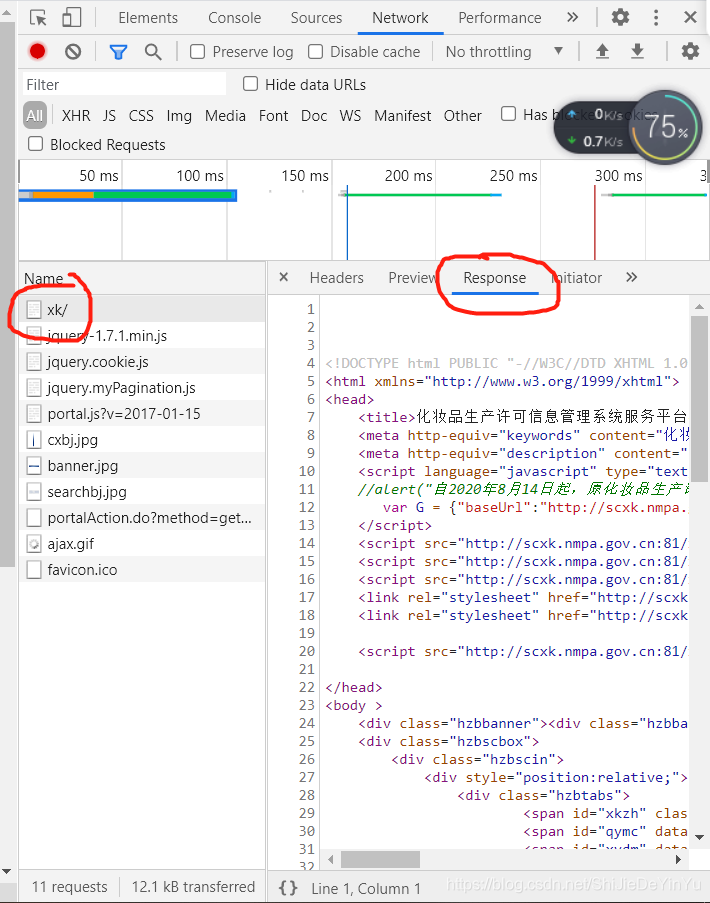
然后在按下 “ctrl” + “F”,开始查找
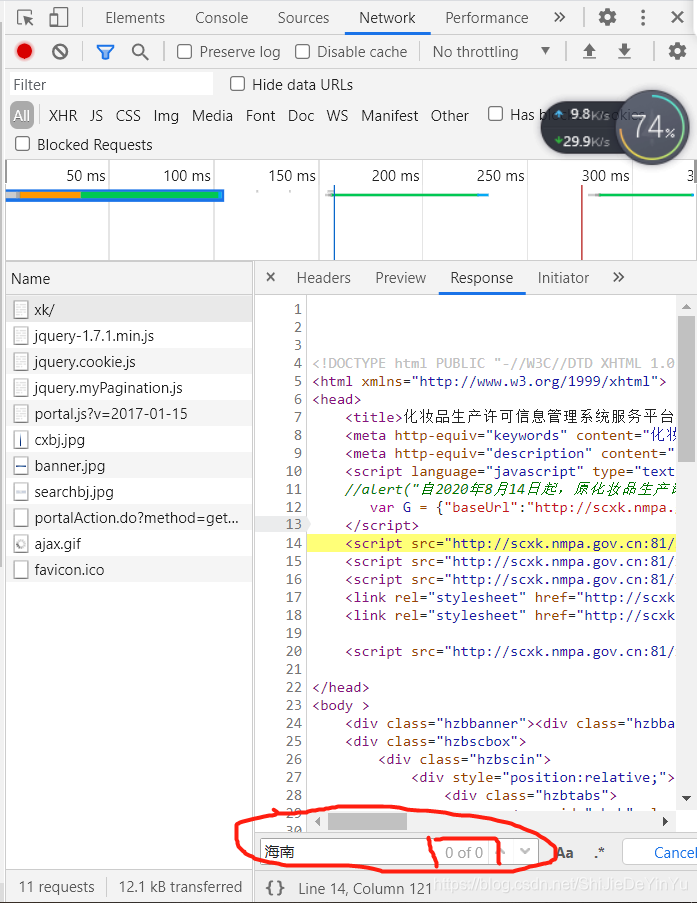
我们发现网页源码上并没有 “海南” , 但我们的公司名称里却有,这说明,我们对应的 url 并不能获取我们需要的数据,那么这些数据在哪里呢?不知道你们有没有想到我们前面提到过的 AJAX。好吧,既然我们没有别的办法,那就试试喽。
结果这一看真是不得了。

response 里的 json 不就是我们想要的吗?赶紧兴奋地去在线解析一下
我们会发现这些数据里面的 ID 特别显眼,然后再回到我们公司的具体信息的页面,一看,我的天呀,这是什么啊。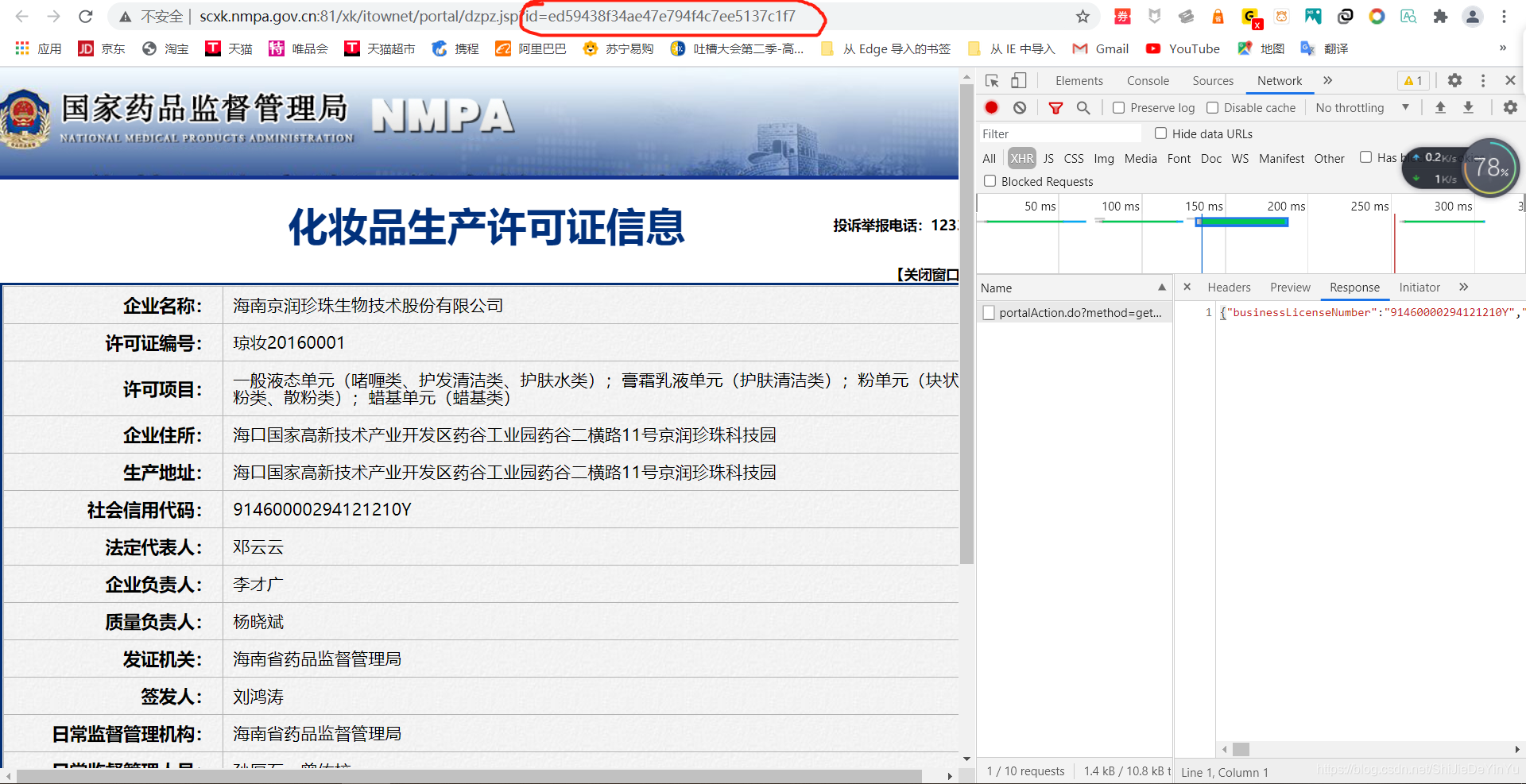
这不就是我们要的 url 里的动态部分吗?别太激动了,试验一下。

一验证,发现果然如此,这不得仰天长啸一翻,天不亡我。
好了,既然得到了这些信息,我们是不是就可以写代码了吗?
当然你要写没有拦你,但你打开一看自己得到的数据或是网页,就会发现,结果和前面一样,没有任何数据。然后我们再一次重复上面的数据就会发现数据还是被保存在 XHR 的请求中,是不是特别想说一句 “ 禁止套娃 ”?
不管有多少脏话要骂,还是要写代码,唉,要不边写边骂?
代码如下:
import requests
if __name__ == "__main__":
# UA 伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定 XHR 的 url
url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList"
# data
data = {
"on": "true",
"page": "1",
"pageSize": "15",
"productName": "",
"conditionType": "1",
"applyname": "",
"applysn": ""
}
# 存储最后的 ID 数据
id_list = []
for page in range(1, 3): # 翻两页
data["page"] = str(page)
# 发送请求命令,获取 json 数据
data_json = requests.post(url, data = data, headers = header).json()
# 分析一下 json 数据的结构
data_list = data_json["list"]
for i in data_list:
id_list.append(i["ID"])
# 公司具体信息网页的 XHR 中的 url
new_url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById"
data = {
"id": "5eb10afc74a2462c8e86652ec8d90a48"}
for ID in id_list:
data["id"] = ID
# 发送请求
response = requests.post(new_url, data = data, headers = header).json()
# 这是一个json串,我们可以先在线解析,再保存我们想要的东西
name = response["epsName"]
# 保存
with open(".公司信息.text", "a", encoding = "utf-8") as fp:
fp.write("公司名称:" + response["epsName"] + "\n" + "公司地址:" + response["epsProductAddress"] + "\n" + "法定代表人:" + response["legalPerson"] + "\n" + "\n")
# 提示
print(name + "的信息下载完成!!!")
我们运行一下程序,结果如下:
打开文件一看



