肯德基餐厅地址查询
前面我们学习了破解百度翻译,知道了 AJAX 的工作原理和爬取,那么我们今天就来巩固我们的学习成果吧。
首先我们打开肯德基的官网,点击 “餐厅查询”
然后是没有地址的网页,然后我们输入地址
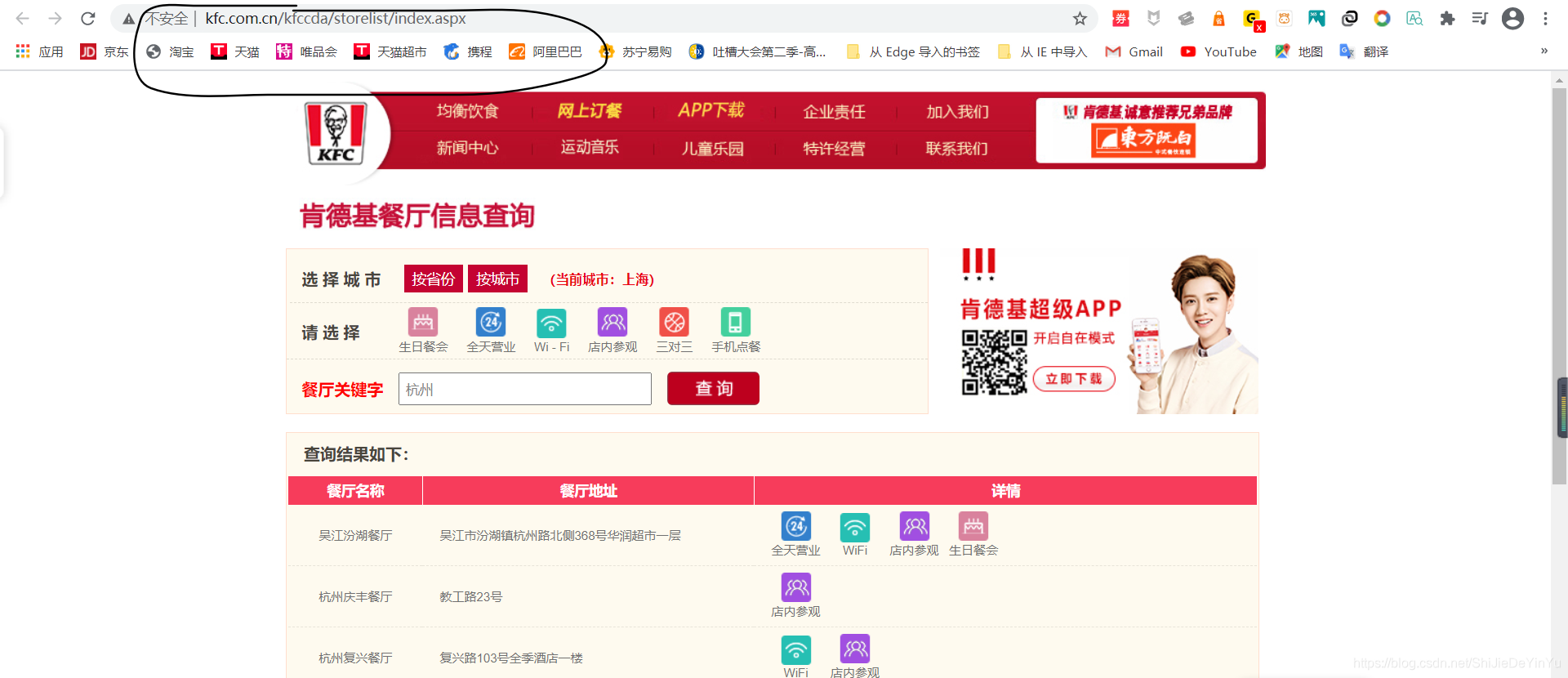
我们发现不论有没有搜索,网址都没有发生变化,这说明肯德基官网的地址查询是通过 AJAX 实现的,知道了这样一点我们就可以使用抓包工具进行分析了。
我们可以从抓包工具中找到请求的 url 和相对应的请求命令和数据类型。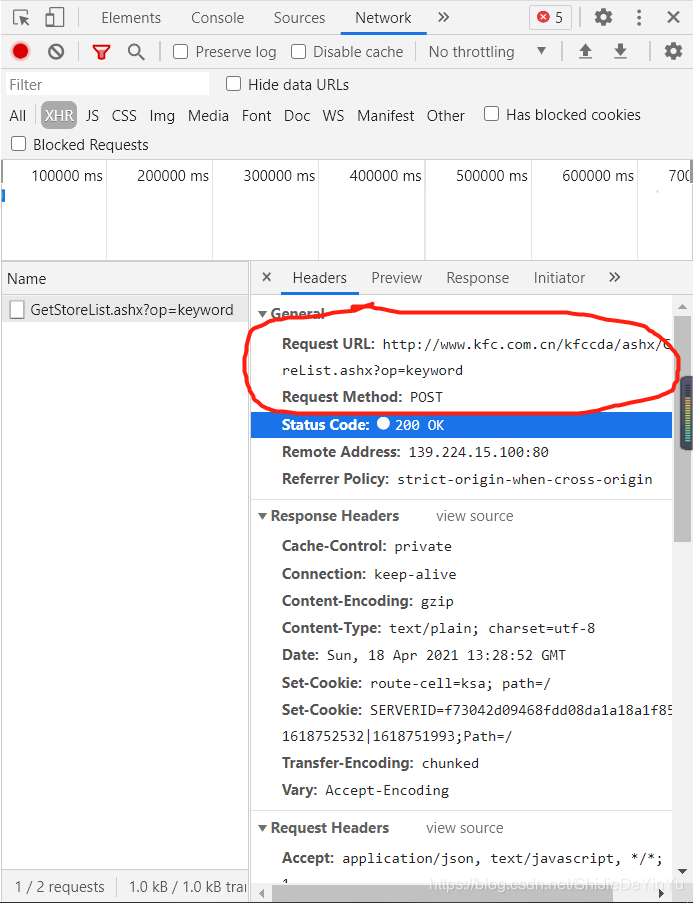
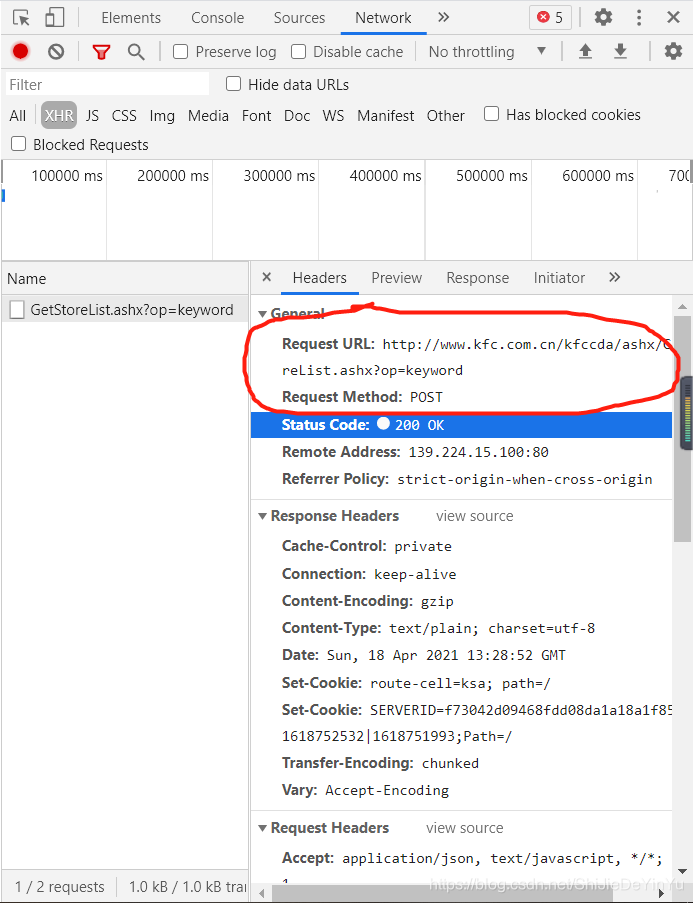

我们发现这是一个 json 串,我们还需要像上次破解百度翻译一样先把 json 串爬取下来,再在线解析吗?答案当然是否定的,我们可以在抓包工具的 response 中得到目前的 json,然后在线解析。

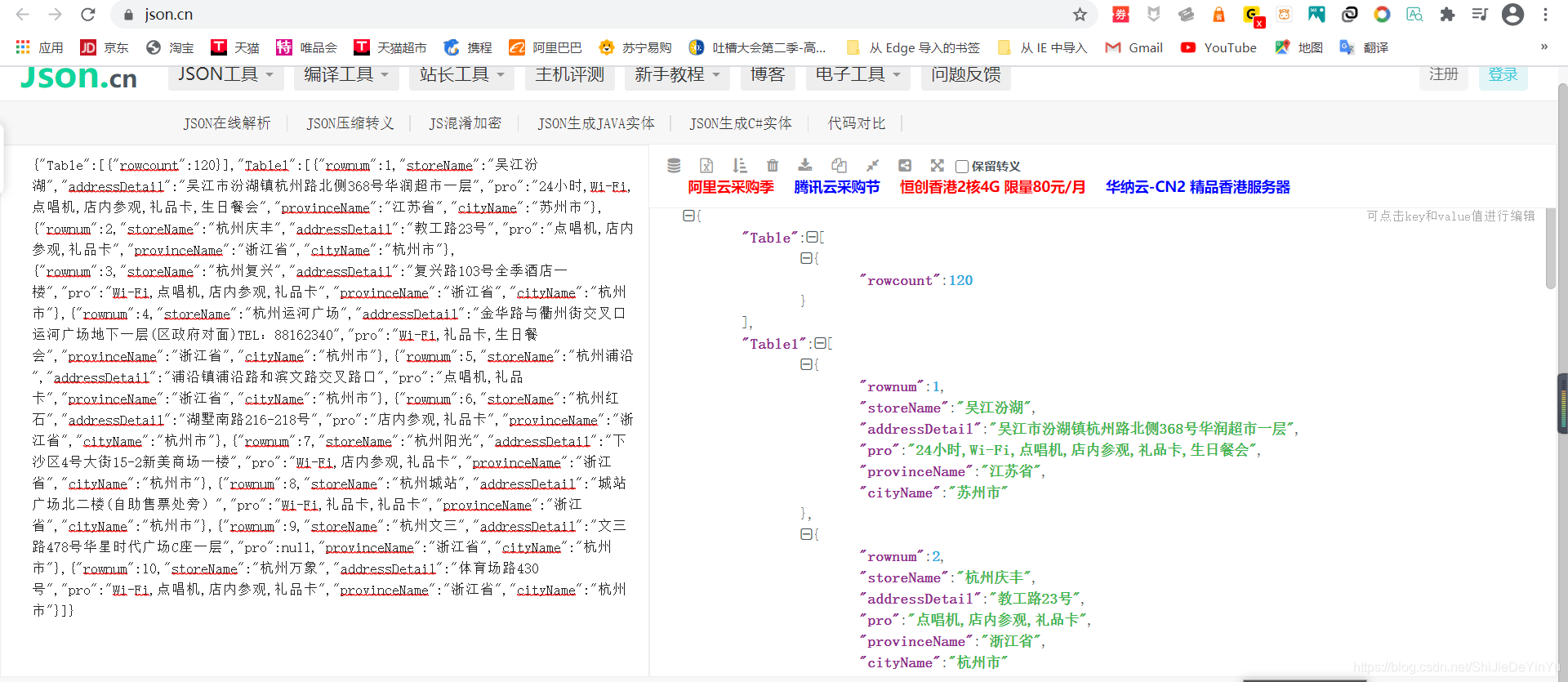
欧克,那么我就可以开始写爬取肯德基餐厅地址的代码了
import requests
if __name__ == "__main__":
# 指定 URL
url = "http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword"
# UA 伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
# 数据
kd = input("需要查询的地点:")
data = {
"cname": "",
"pid": "",
"keyword": kd , # 要搜索的地址
"pageIndex": "1" , # 要爬取的网页的页码
"pageSize": "10" # 每一页的数量
}
# 发送请求
for i in range(1, 3): # 爬取两页
data["pageIndex"] = str(i)
response = requests.post(url = url, data = data, headers = header).json()
page = response["Table1"]
# 存储
for detail in page:
with open("./肯德基地址.txt", "a", encoding = "utf-8") as fp:
fp.write("storeName:" + detail["storeName"] + "\n" + "addressDetail:" + detail["addressDetail"] + "\n" + "\n")
print("over!!!")
打开保存的文件如下
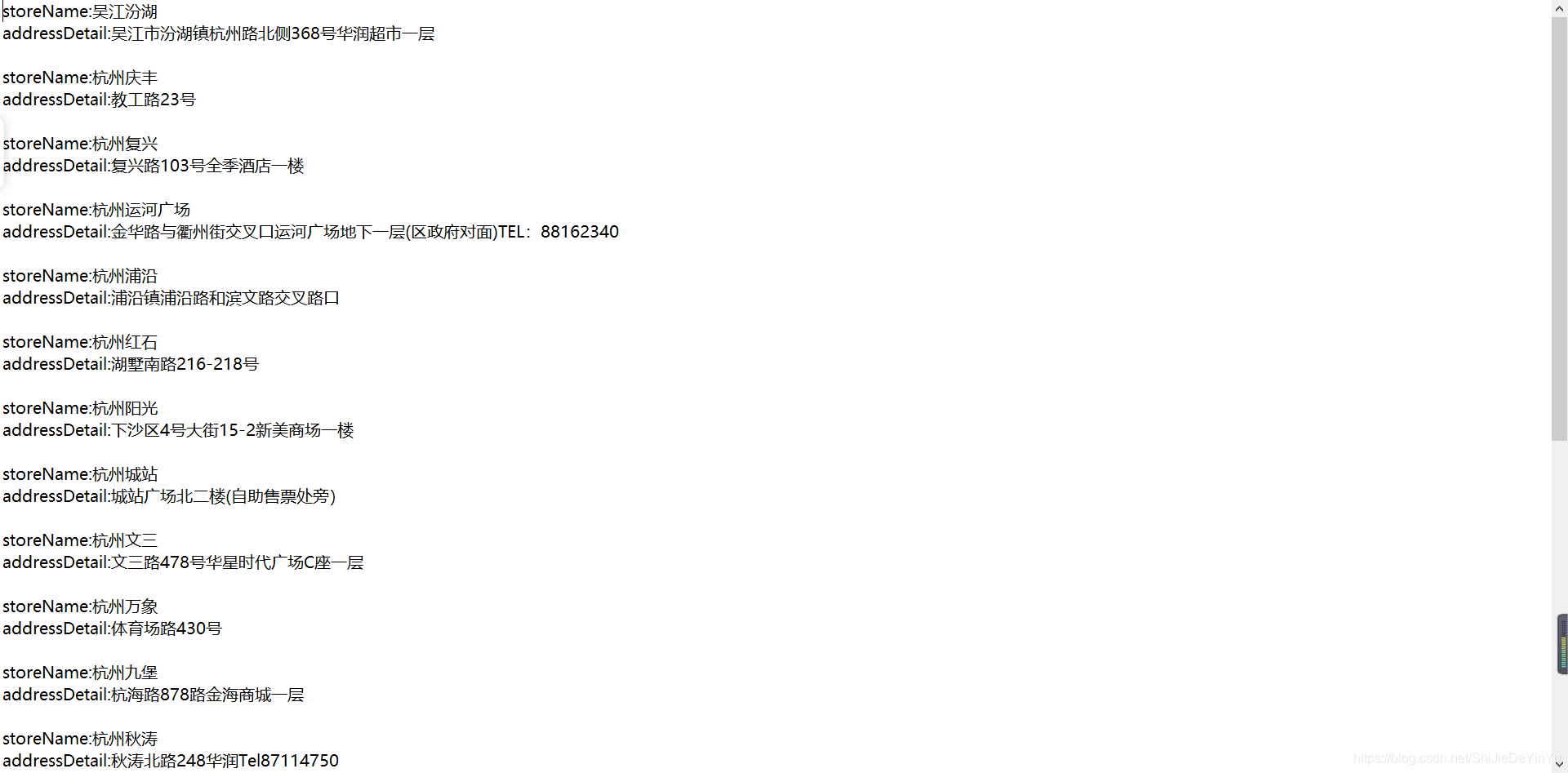
说明爬取成功



