“破解”百度翻译
翻译是一件麻烦的事情,如果可以写一个爬虫程序直接爬取百度翻译的翻译结果就好了,可当我打开百度翻译的页面,输入要翻译的词时突然发现不管我要翻译什么,网址都没有任何变化,那么百度翻译要怎么爬取呢?
爬取百度翻译之前,我们先要明白百度翻译是怎么在不改变网址的情况下实现翻译的。百度做到这一点是用 AJAX 实现的,简单地说,AJAX的作用是在不重新加载网页的情况下进行局部的刷新。
了解了这一点,那么我们要怎么得到 AJAX 工作时请求的URL呢?老规矩,使用抓包工具。步骤如下:
- 在 “百度翻译” 页面右键,选择“Notework”
- 选择 “ XHR ”
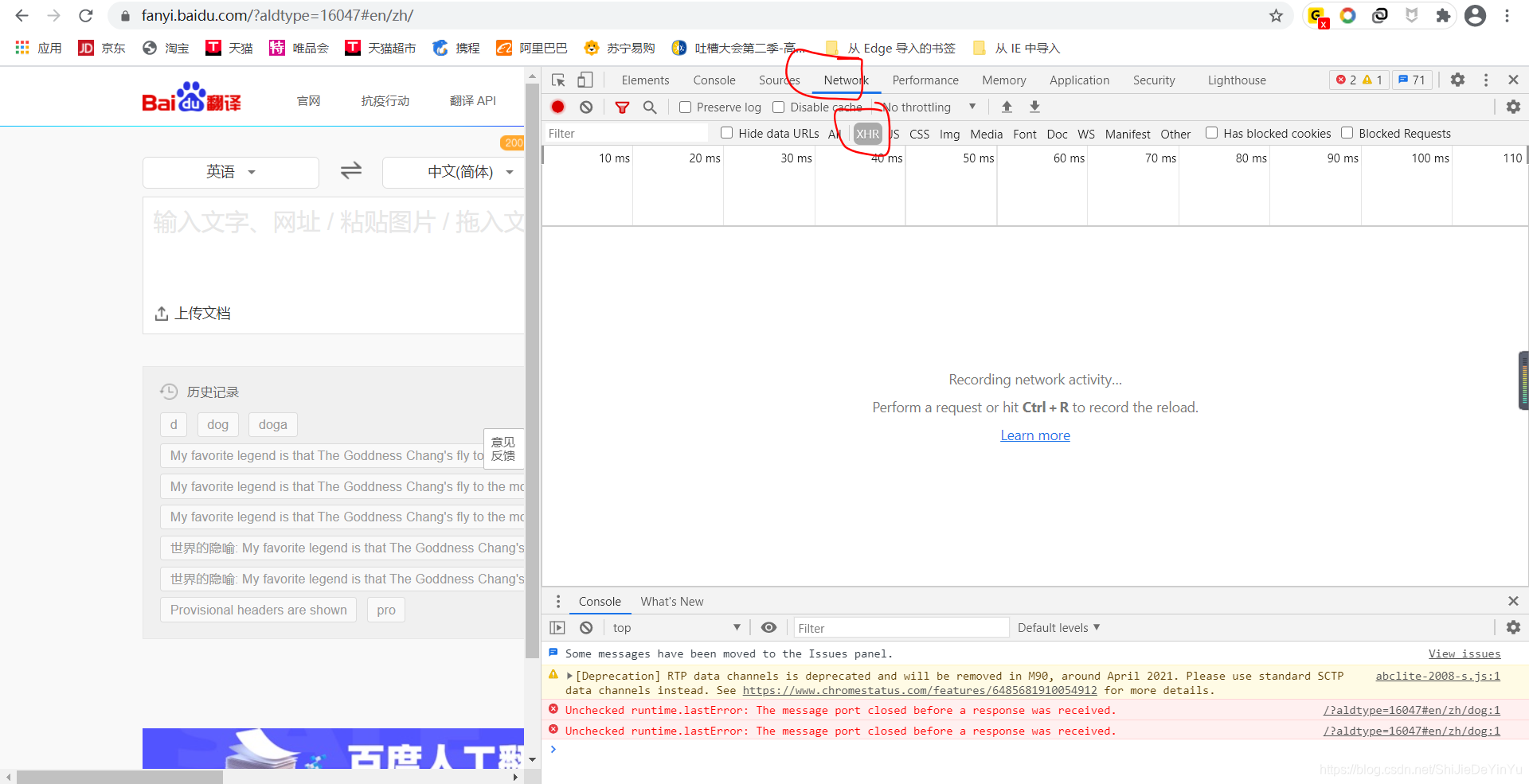
- 如果画面没有任何数据,可以试着输入要翻译的词,比如说我输入“dog”时,就发生了如下的变化
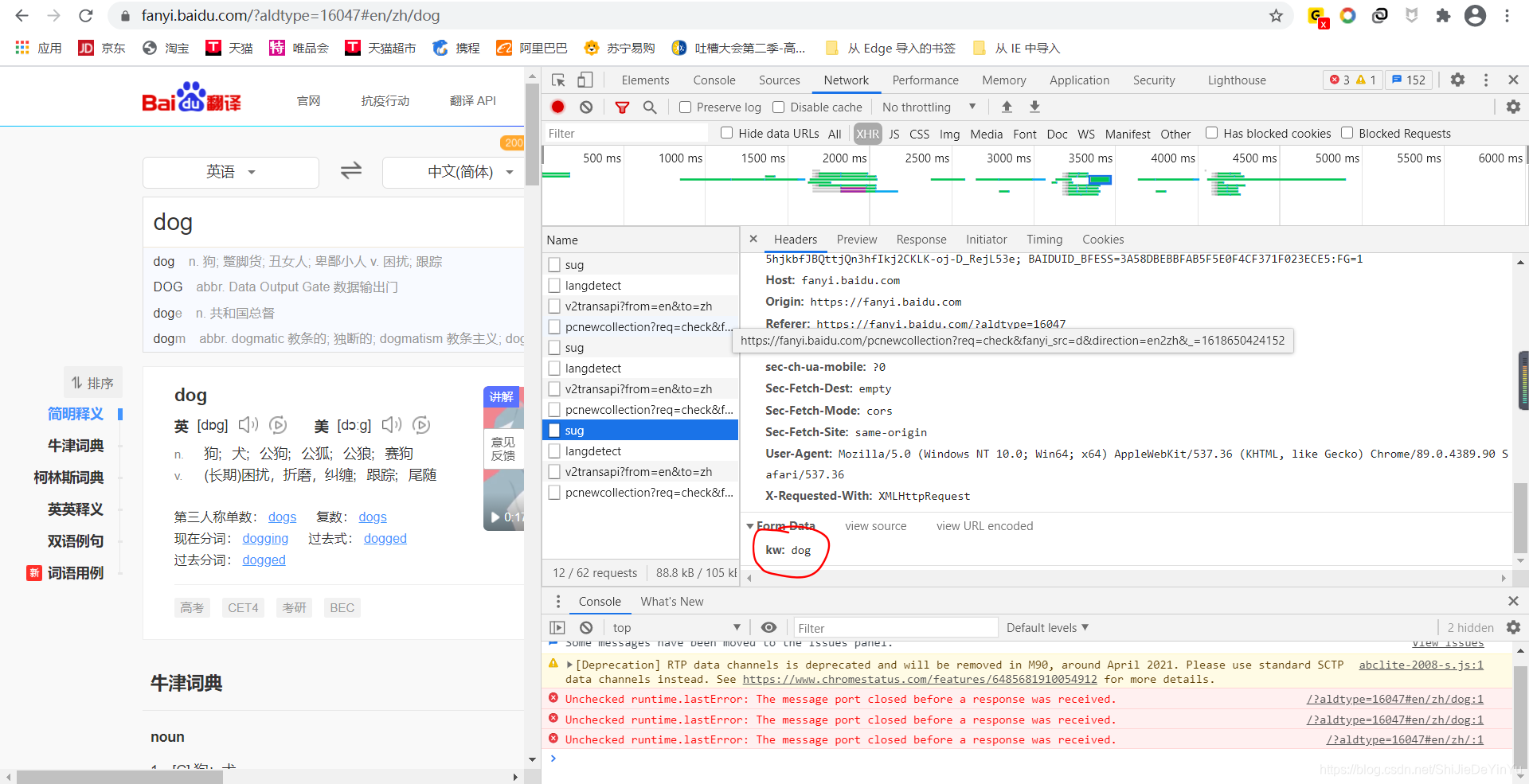
我们看到此时的 kw 是我要翻译的词,说明这是我们要找的东西。
(注意:我们发现其中有三个 sug ,我选的只是其中一个。如果我们全都带点开看,就会发现,他们的 kw 分别是:d 和 do。这是因为我打 dog 时一个单词一个单词打的,而 AJAX 是时时刷新。如果输入中文就不会出现这种情况。翻译中文时,我们找的也不是 sug 了,具体是什么,就看哪个包的 data 的值是我们要翻译的词。)
然后我们在回到上面,找到我们需要指定的 URL 、我们要选择的请求命令以及爬取到的数据的类型。
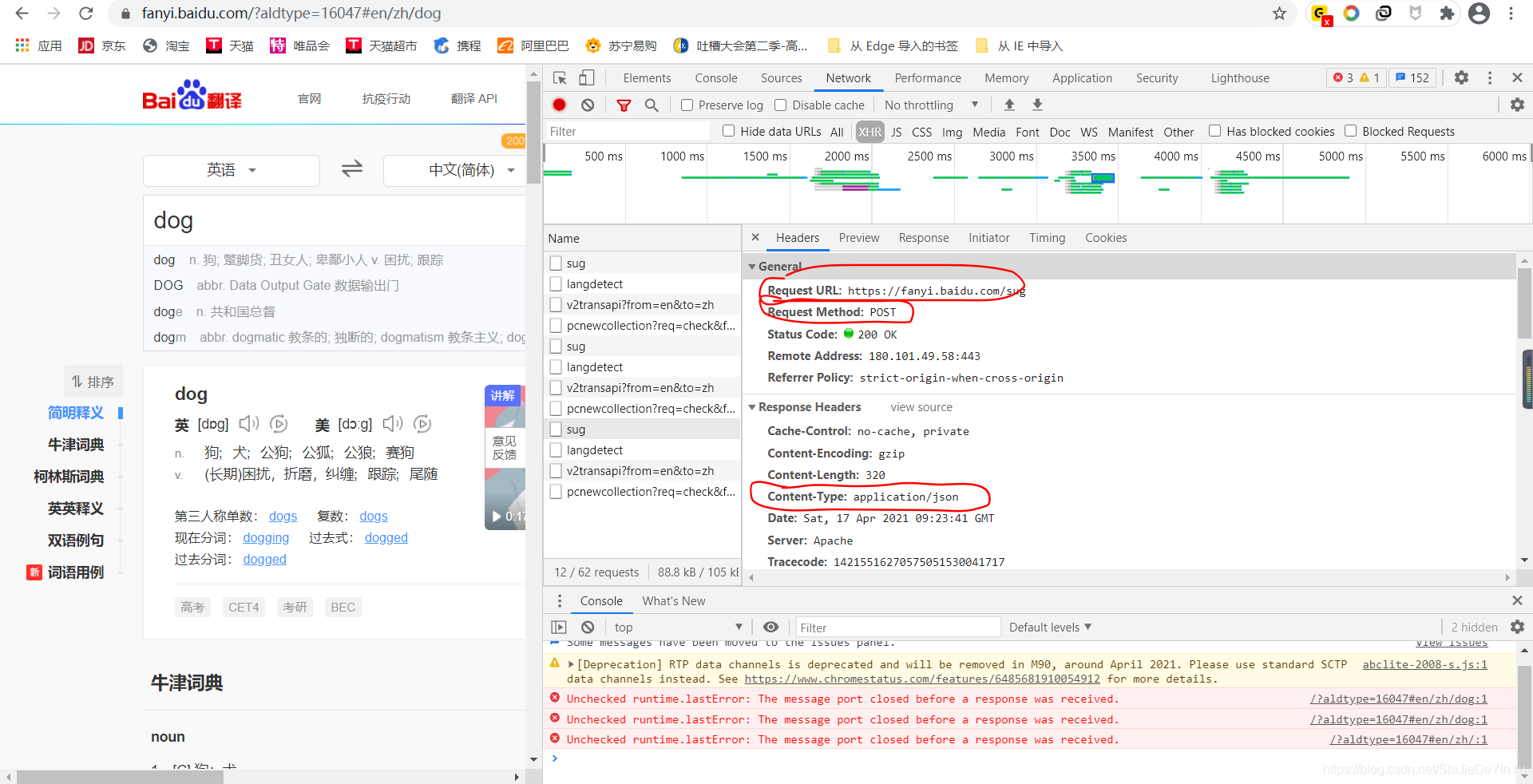
欧克,做到这里我们的前期准备就完成了,下面就可以开始着手写代码了。
import requests
if __name__ == "__main__":
# 指定 url
url = "https://fanyi.baidu.com/sug"
# 要翻译的词
keyword = input("需要翻译的词:")
data = {
"kw": keyword
}
# UA 伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
# 发送请求
response = requests.post(url = url, data = data, headers = header).json()
print(response)
我们运行程序发现结果是这样的:
因为请求到的数据比较短,所以我们比较容易地看出数据的结构是字典里有列表,列表里又有字典结构。如果比较长,我们可以使用在线 json 转换,转换后的数据是这样的
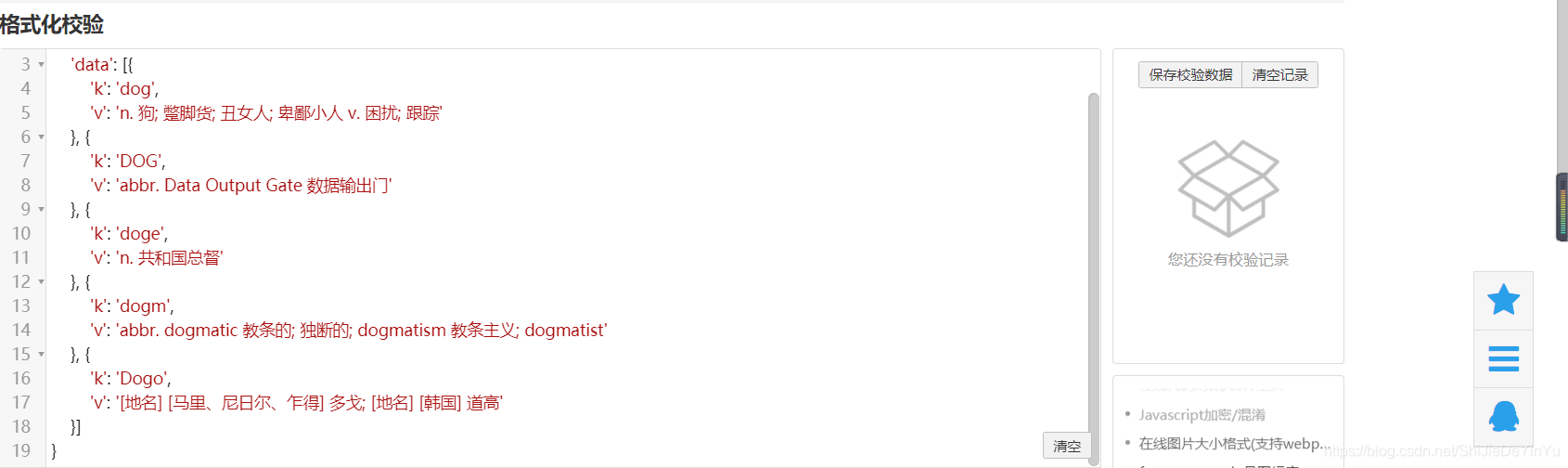
我们只需要 dog 的释义,所以我们还可以对我们代码进行优化
print(response["data"][0]["v"])
注意:
关于 data 的字典,并不是说只需要 “ kw ”: dog, data 的字典里要存储的是抓包工具里 from data 里所有的值,如果没有值,那么相对应的值就是空字符串。



