上一篇的翻页爬取图片代码
话不多说,直接上代码
import requests
import re
import os
if __name__ == "__main__":
# 创建文件夹
if not os.path.exists("./糗图(翻页)"):
os.mkdir("./糗图(翻页)")
# UA 伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定 url
for index in range(1, 3): # 翻两页
url = "https://www.qiushibaike.com/imgrank/page/%s/" % str(index) # 我们观察不同页数的网址会发现不同页数的网址的差异在于最后的数字
# 发送请求
page = requests.get(url = url, headers = header).text
# 正则解析
ex = '<div class="thumb">.*?<img src="(.*?)" alt=".*?</div>'
data_list = re.findall(ex, page, re.S)
# print(data_list) # 试着打印看看这是不是我们需要的东西
# 指定图片的 url
for i in data_list:
new_url = "https:" + i
title = i.split("/")[-1]
path = "./糗图(翻页)/" + title
# 发送请求
photo = requests.get(url = new_url, headers = header).content
# 保存
with open(path, "wb") as fp:
fp.write(photo)
print(title, "下载完成!!!")
print("over!!!")
爬取《三国演义》
爬取图片难道就可以满足我们了吗?俗话说的好,书中自有黄金屋,书中自有颜如玉。只爬取妹子图怎么可以满足我?要来就干票大的,钱和美女我都要!!!那么说来就来,就让我们来爬取《三国演义》吧。
首先我们打开《三国演义》的目录发现所有的章节都是一个超链接,所以我们需要对该网址进行数据解析,得到所有章节的url,然后对新的 url 进行数据解析,得到网址中的所有文本信息。
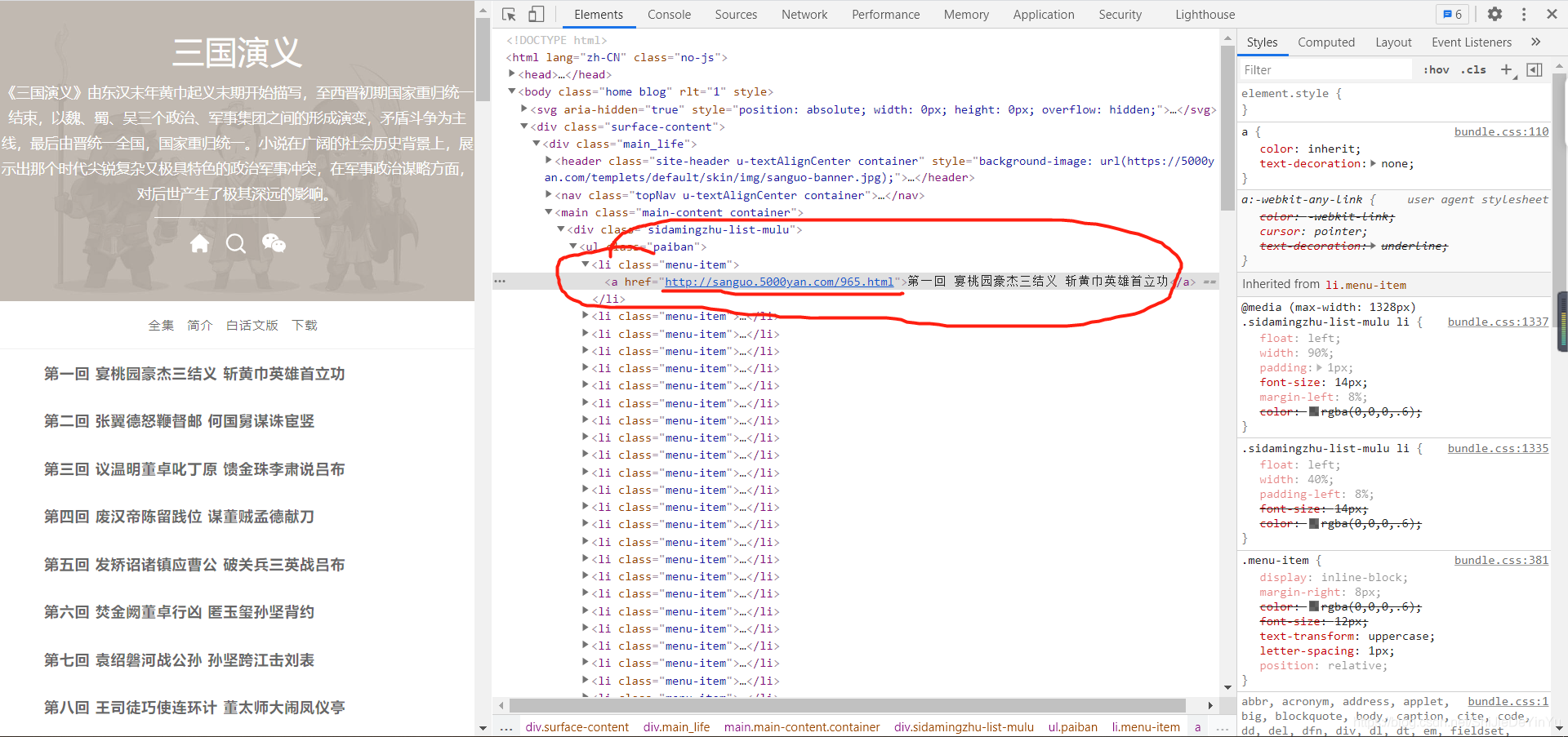

思路比较简单,了解之后,就可以直接写代码了
import requests
import re
if __name__ == "__main__":
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定url
url = "http://sanguo.5000yan.com/"
# 发送请求
page = requests.get(url = url, headers = header)
page.encoding = "utf-8" # 编译源码,不然我们得到的就是一些乱码
page = page.text
# 正则解析
ex = '<li .*? href="(.*?)">(.*?)</a></li>'
new_url_list = re.findall(ex, page, re.S)
# print(new_url_list) # 测试是否为我们要的 url
for new_url in new_url_list[4:]:
title = new_url[1]
new_page = requests.get(url = new_url[0], headers = header)
new_page.encoding = "utf-8" # 编译源码,不然我们得到的就是一些乱码
new_page = new_page.text
ex = '<div>(.*?)</div>'
page_text = re.findall(ex, new_page, re.S)
# 存储
with open("./三国演义.txt", "a", encoding = "utf-8") as fp:
if title == "第一回 宴桃园豪杰三结义 斩黄巾英雄首立功":
fp.write(title + ":" + "\n" + "\n")
else:
fp.write("\n" + "\n" + title + ":" + "\n" + "\n")
# 因为我们用正则表达式得到的数据里有超链接,所以我们需要把这些都替换掉
for sencetence in page_text:
sencetence = re.sub(r"<.*?>", "", sencetence)
sencetence = re.sub(r"—", "—", sencetence)
sencetence = re.sub(r" ", "", sencetence)
sencetence = re.sub(r"“", "“", sencetence)
sencetence = re.sub(r"”", "”", sencetence)
sencetence = re.sub(r"\s", "", sencetence)
with open("./三国演义.txt", "a", encoding = "utf-8") as fp:
if sencetence != "":
fp.write("\n" + "\t" + sencetence)
print(title, "下载完成!!!")
运行结束后,我们打开文件,结果如下。




