正则解析爬取图片
因为讲的是正则解析,而不是正则表达式,所以我就默认大家会正则表达式了。最多在这里给大家看一下正则的语法。
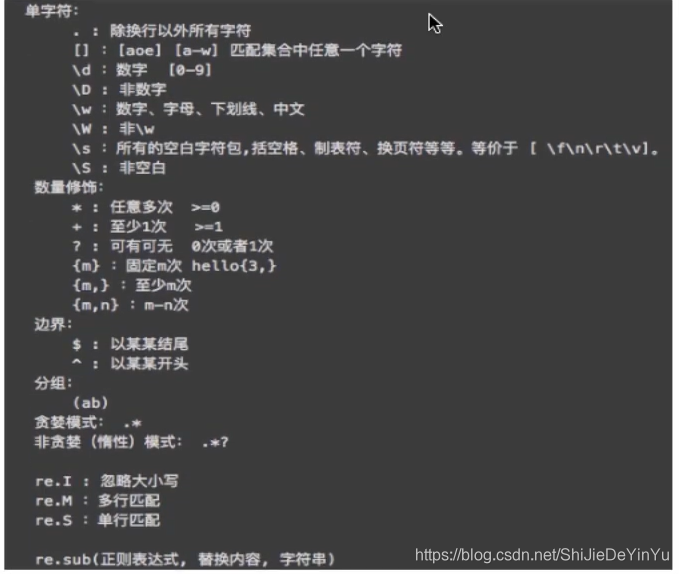
这也是我从B站上截图截下来的。因为我自己都是学的半懂不懂的,实在没那脸说在这里讲正则表达式怎么写。
如果感觉学不会怎么办?没事,我们 python 的数据解析有正则解析、bs4解析和 xpath 解析。总有一款适合你。(这些后面都会讲到)
言归正传,什么是数据解析,在我看来,数据解析简单来说就是分析网页的源代码。
还记得像套娃一样的药监局吗?我似乎说过可以通过数据解析解决。欧克,那就让我们看一下,数据解析这么解决这个问题。
先点击左边圈起来的有鼠标样式的按键,将它移到我们的公司超链接上单击。神奇的事情发生了。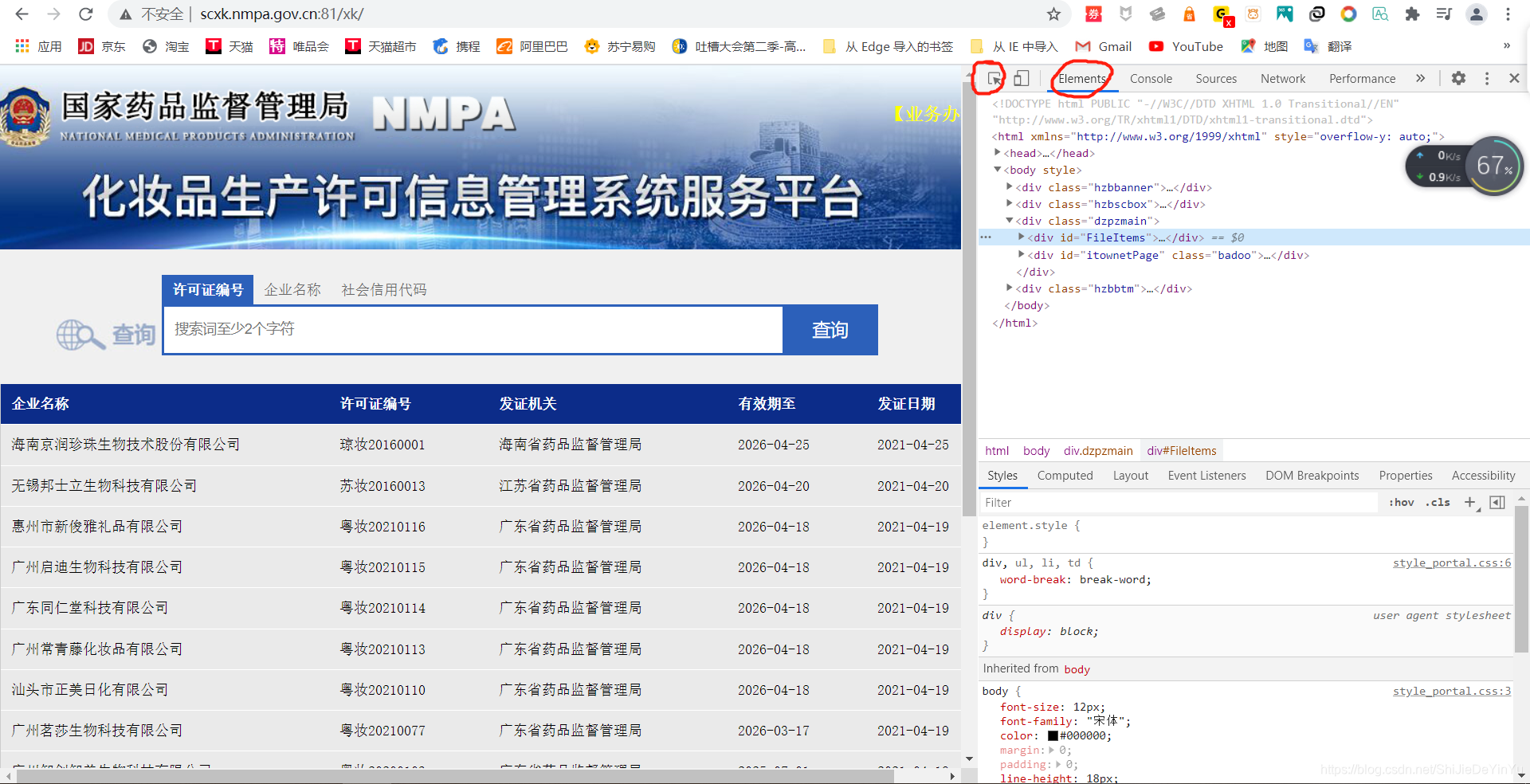
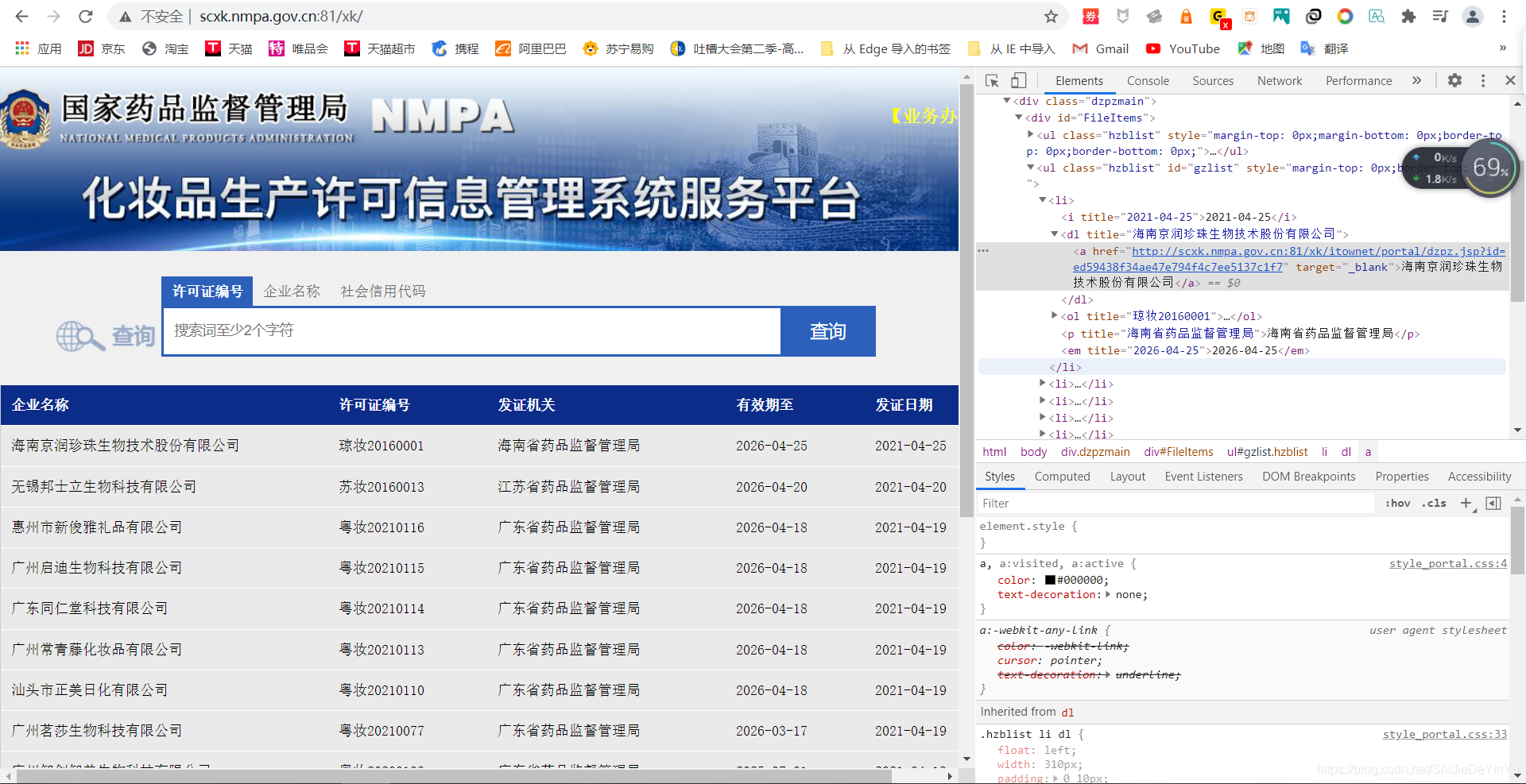
我们看到了一个网址,我们直接点击网址看看会发生什么。
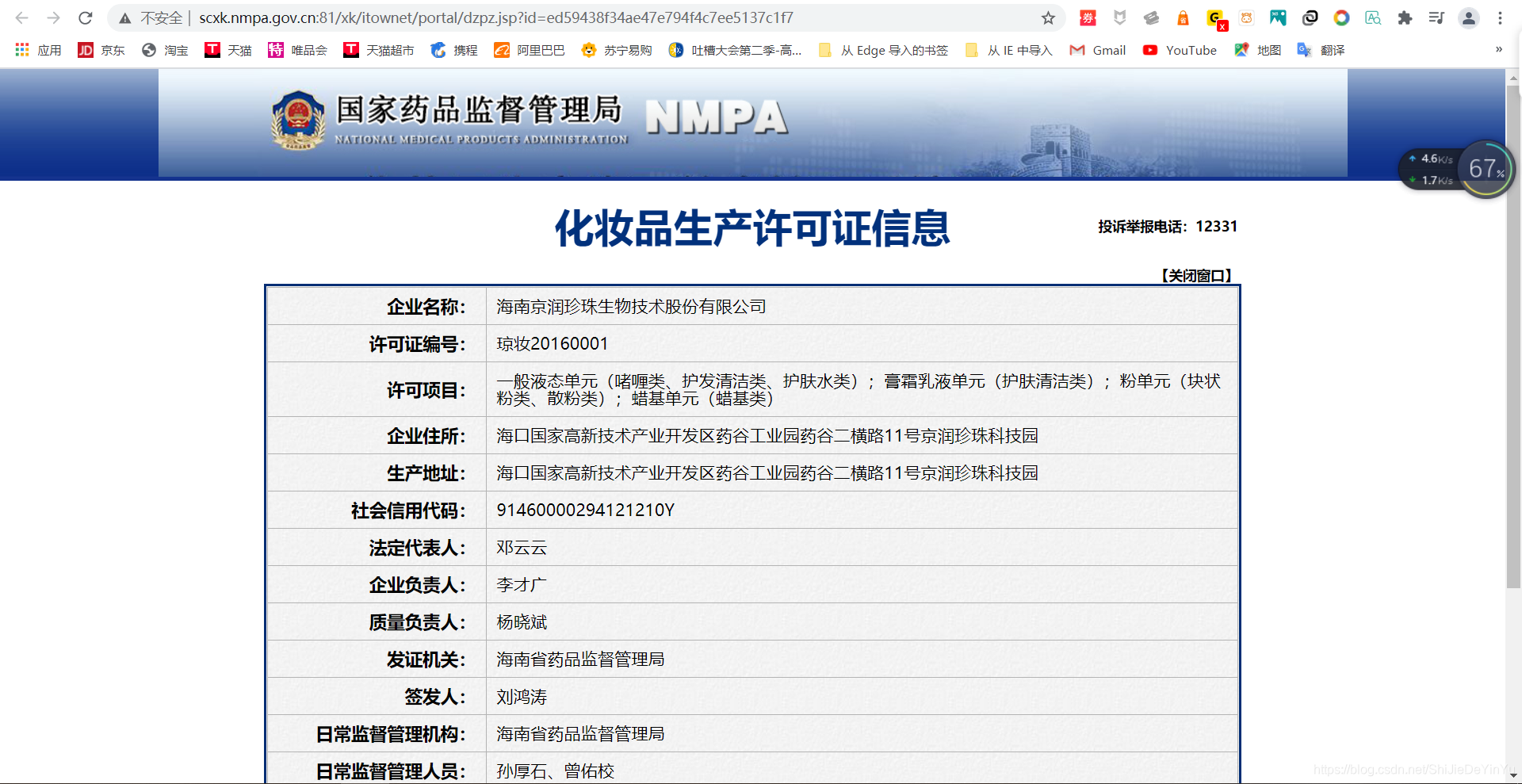
哦豁,我们来到了这个页面,然后我们重复的步骤,将鼠标移到我们要爬取的数据上单击,然后我们就在网页上看到了我们要爬取的文本。
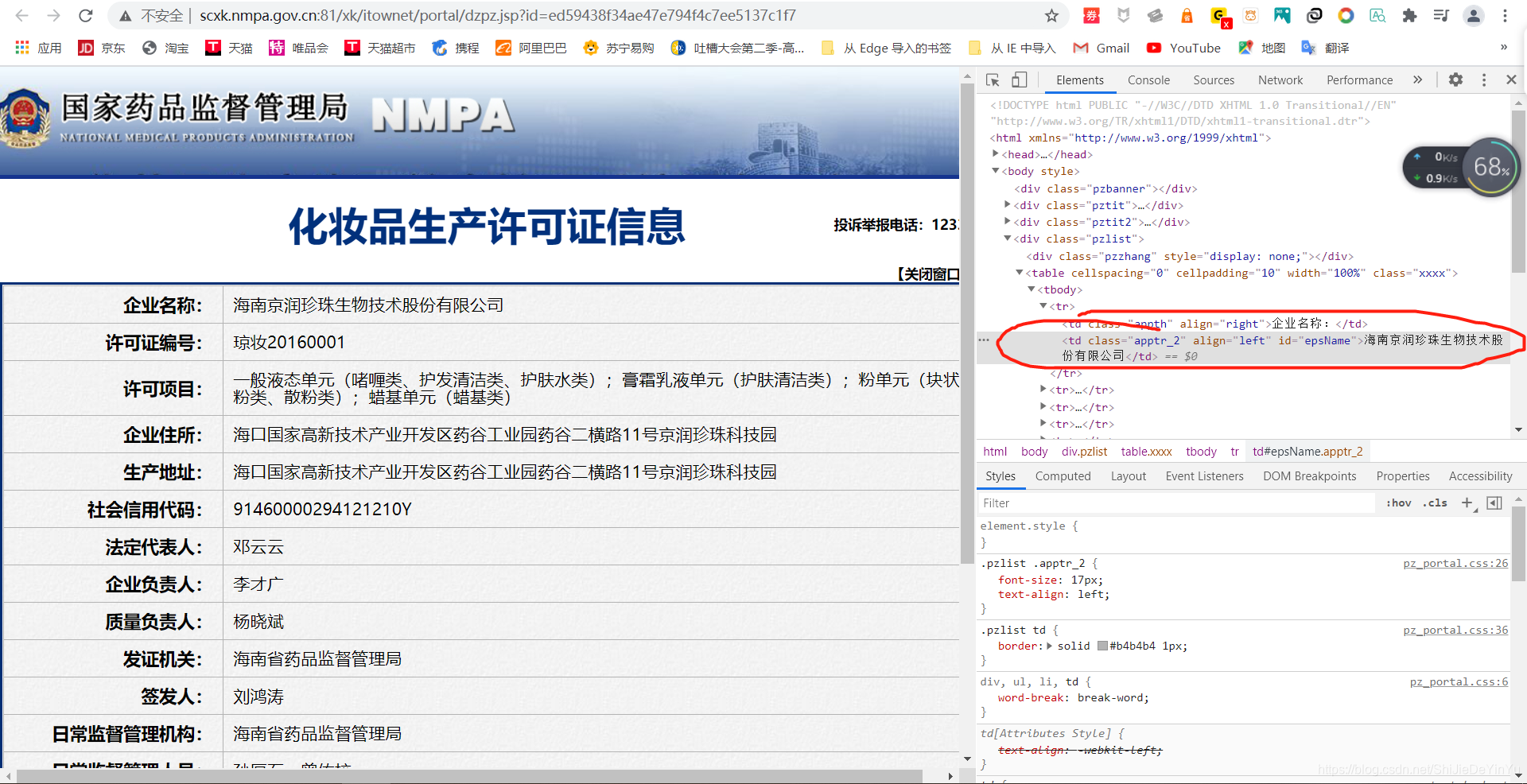
那我们是不是只要爬取我们在网页源码上看到的文本就可以了。是不是很简单?你要套娃?我直接开拆,是不是很有趣?
那我们前面学的 requests 模块是不是没什么用?
当然不是,爬取整张网页不是 requests 简单吗?再说就算有数据解析,有时候也不见得简单。比如说百度翻译,你可以试试用数据解析爬取,相信我,还不如分析它的 XHR 。
当然我们今天不搞药监局,天天看文字,不得恶心?今天我们来爬取图片。嘿嘿嘿嘿,图片~。我们今天的目标是妹子,哦不,是糗图网(https://www.qiushibaike.com/imgrank/)。
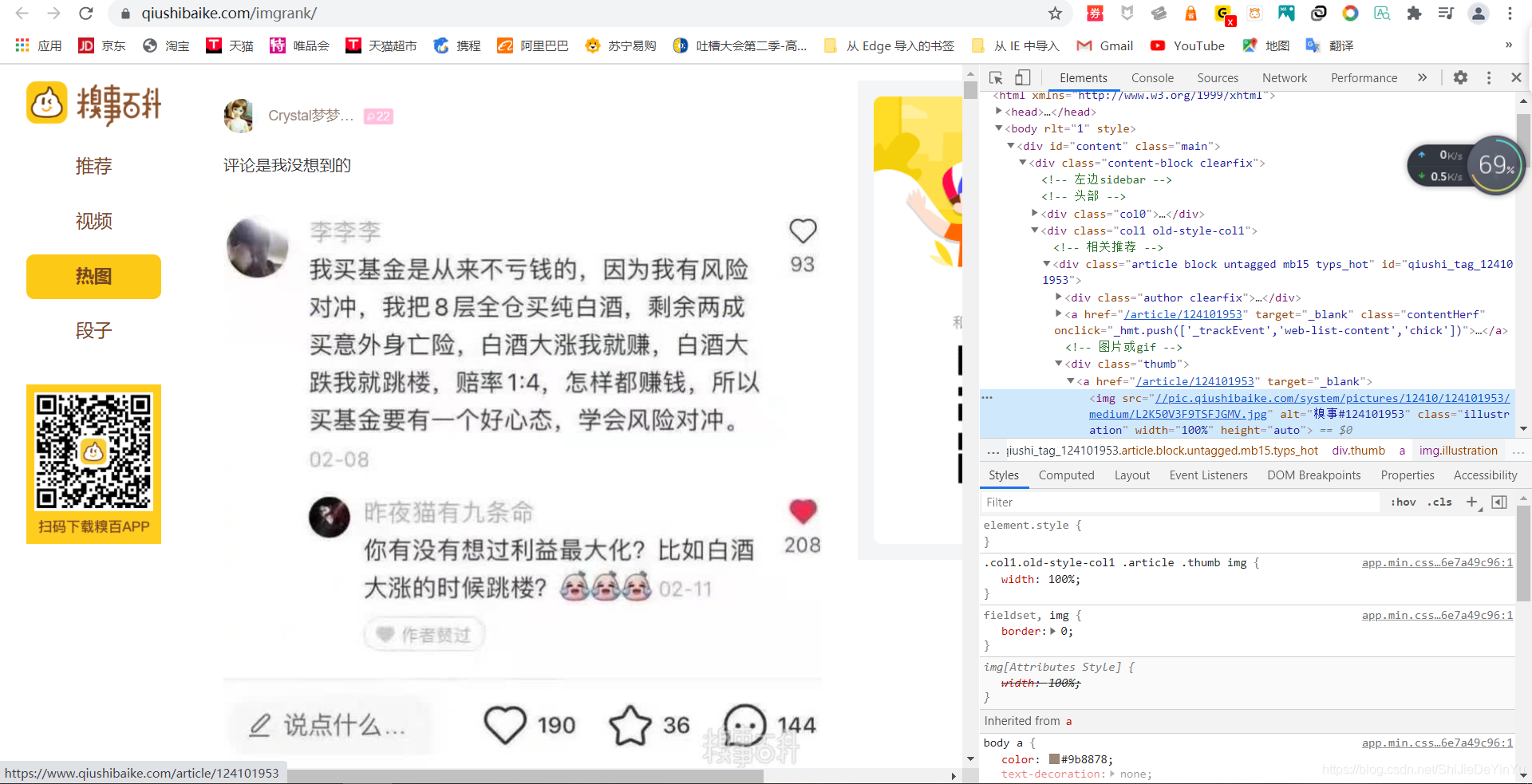
首先我们定位到一张图片,复制我们看到的链接,在前面加上 ” https: “ 会发现这就是我们需要的爬取东西。那么我们怎么爬取呢?很简单,在网页的源代码中查找。
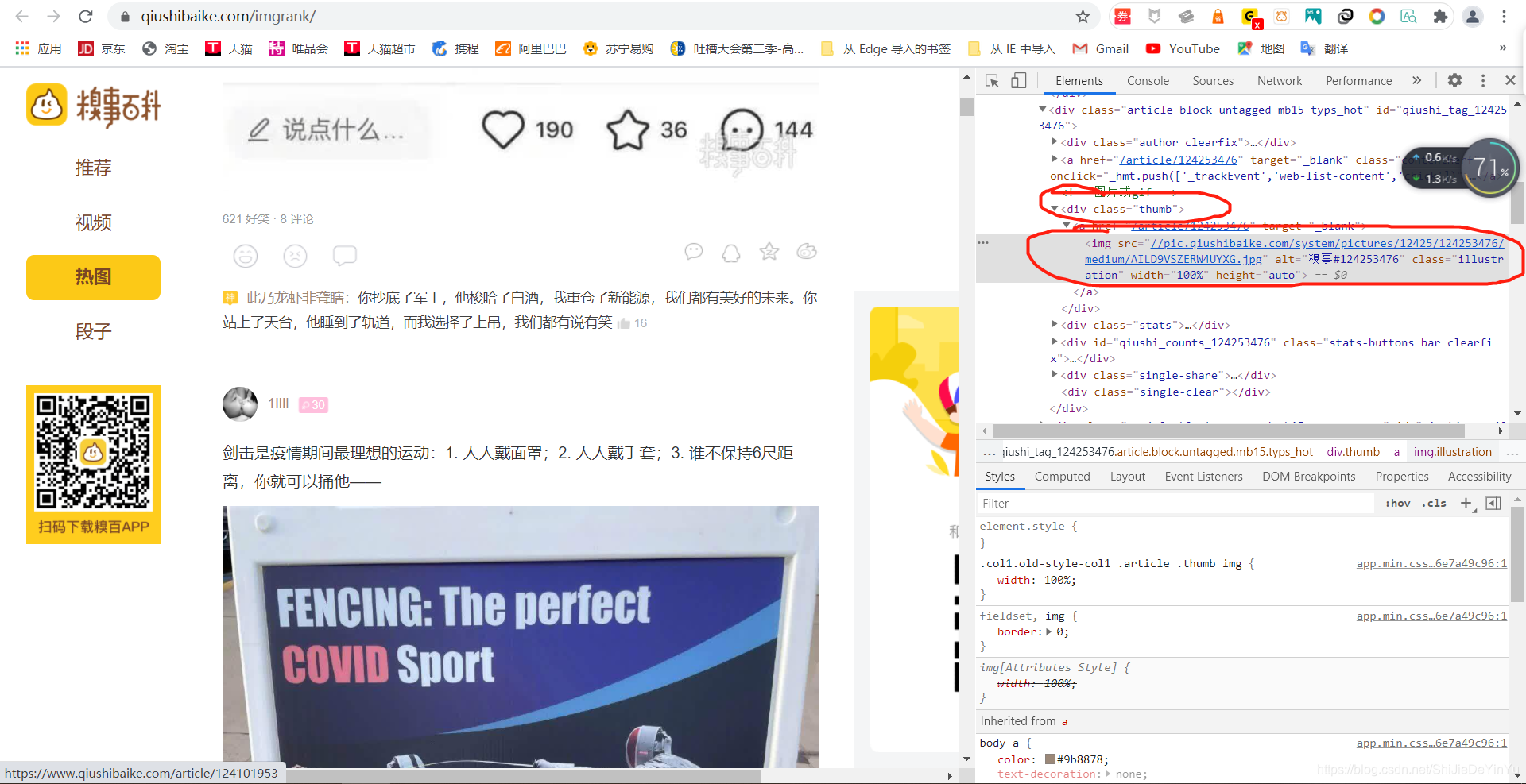
如果我们试着去定位多个图片的源码位置,我们会发现所有我们需要的数据都在标签<div class= "thumb"下面的<img src里面,这时候我们就可以发挥正则表达式的强大作用了。
话不多说,直接上代码
import requests
import re
import os
if __name__ == "__main__":
# 如果不存在这个文件,创建一个文件夹
if not os.path.exists("./糗图"):
os.mkdir("./糗图")
# UA 伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定 url
url = "https://www.qiushibaike.com/imgrank/"
# 发送请求,获取网页源码
page_text = requests.get(url = url, headers = header).text
# 对源代码进行正则解析
ex = '<div class="thumb".*?<img src="(.*?)" alt=".*?</div>'
data_list = re.findall(ex, page_text, re.S) # re.S 是必要的,因为我们是要单行查找
# print(data_list) 我们可以先打印看看是否符合要求
# 在爬取到的内容前加上 “https:”形成新的 url
for data in data_list:
new_url = "https:" + data
title = data.split("/")[-1]
# 请求命令
photo = requests.get(url = new_url, headers = header).content # conntent 命令是为了将爬取到的数据转换成数据流
path = "./糗图/" + title
# 保存
with open(path, "wb") as fp:
fp.write(photo)
print(title, "下载完成!!!") # 给一个下载完成的提示
print("over!!!")
然后我们查看新建的文件夹
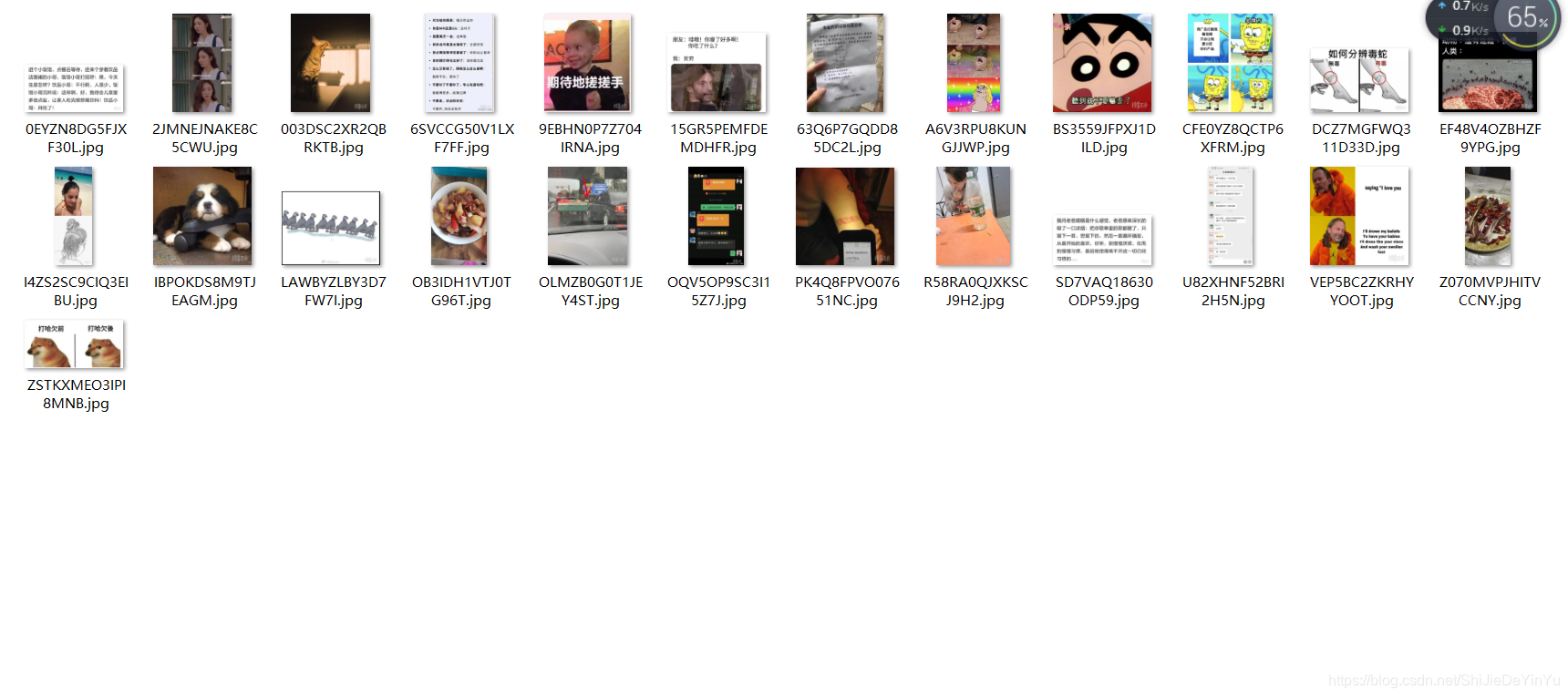
这说明我们成功了。当然我们只爬取了一页网页的图片,如果我们要爬取动态的网页的图片要怎么做呢?
给个提示,观察一下第二页第三页网址的区别。
这不得自己试着写一下。



